Specious Sites: Tracking the Spread and Sway of Spurious News Stories at Scale
Hans W. A. Hanley
hhanle[email protected]d.edu
Stanford University
Deepak Kumar
kumar[email protected]d.edu
Stanford University
Zakir Durumeric
[email protected]d.edu
Stanford University
Abstract—Misinformation, propaganda, and outright lies pro-
liferate on the web, with some narratives having dangerous
real-world consequences on public health, elections, and indi-
vidual safety. However, despite the impact of misinformation,
the research community largely lacks automated and program-
matic approaches for tracking news narratives across online
platforms. In this work, utilizing daily scrapes of 1,334 unre-
liable news websites, the large-language model MPNet, and
DP-Means clustering, we introduce a system to automati-
cally identify and track the narratives spread within online
ecosystems. Identifying 52,036 narratives on these 1,334 web-
sites, we describe the most prevalent narratives spread in
2022 and identify the most influential websites that originate
and amplify narratives. Finally, we show how our system
can be utilized to detect new narratives originating from
unreliable news websites and to aid fact-checkers in more
quickly addressing misinformation. We release code and data
at https://github.com/hanshanley/specious-sites.
1. Introduction
Over the last decade, spurious, misleading, and out-
right false information has spread throughout online ecosys-
tems [1]. Digital misinformation has influenced elec-
tions [2], promoted bogus health cures leading to unnec-
essary deaths [3], and incited mob violence throughout the
world [4], [5]. Worsening the problem, misleading stories
have been shown to spread at over ten times the rate of true
information [6].
The security community, likening disinformation to an
attack similar to spam, phishing, and censorship [7], [8],
has applied a range of methodologies to ameliorate its
spread [9]–[14]. For example, by examining features similar
to those used to identify spam accounts, researchers have
identified networks of state-propagandists throughout Reddit
and Twitter [11], [15]. However, despite these advances,
most investigations into false narratives remain limited in
scope and retroactive, primarily conducted through time-
consuming, qualitative approaches [16], [17]. To make fun-
damental progress in combating the threat posed by dis-
information, we argue that the security community must
build approaches for tracking the spread of false narratives
globally and in real time.
In this work, we present an NLP-based approach for
programmatically identifying and tracking the spread of
narratives and stories across unreliable news websites and
social media platforms. Between January 1 and November 1,
2022, we crawl a set of 1,334 known misinformation, state-
propaganda, biased, and otherwise unreliable news websites
as well as two fringe forums, 8kun and 4chan. We extract
passages from these news articles, which we embed using an
MPNet model [18] fine-tuned with contrastive learning on
the semantic textual similarity task. Employing a modified
version of the nonparametric algorithm DP-Means, we clus-
ter these embeddings to identify specific narratives/stories.
Our approach enables us to isolate and track 52,036 nar-
rative threads that spread on unreliable news websites during
2022. We do not attempt to determine whether individual
stories are factual, which is a qualitative task that ML-
based approaches have failed to reliably achieve. Rather,
we track all narratives from these specious sites across
online ecosystems and quantify these websites’ influence.
We find, unsurprisingly, that many of the most prominent
narratives in 2022 concerned the Russo-Ukrainian War and
inflation, with websites like southfront.org, rt.com, and ze-
rohedge.com dominating these topics. Identifying which
websites play outsized roles in originating and amplifying
narratives across our set of unreliable news websites, we find
that a website’s popularity has a small correlation with its
ability to propagate narratives with seemingly minor web-
sites like infostormer.com or barenakedislam.com playing
massive roles in popularizing stories.
Next, we investigate how our method can be used to
focus limited investigative resources on the most pernicious
narratives. We show that, like an early detection alarm,
our approach can identify when new narratives emerge.
Comparing when popular false narratives appeared to when
three major organizations (AP News, Reuters, and Politifact)
fact-checked them, we show that our system can prioritize
checking misleading narratives months before their peak
when they first start to gain traction. We hope that this
type of real-time visibility can enable fact-checkers and
journalists to more efficiently track and respond to new,
potentially problematic narratives as soon as they emerge.
Similar to past large-scale empirical analysis in the
security community (e.g., [19]–[28]), our work shows that
a programmatic approach to tracking narratives at scale
uncovers a set of online propagation patterns that would

News Article Daily Document Stream
Article Text and Date
Extraction
Calculate Passage
Embeddings
Update Cluster
Keywords with
Pointwise Mutual
Information and Extract
BART Summary
News
Article
Websites
Separate Document into
Passages
Narrative 1
Narrative 3 Narrative 2
Update Cluster Centers or Create New
Cluster based on Semantic Similarity
to Current Clusters
Common
Crawl
Website
Scrapes, RSS
feeds
Narrative 4
New Narrative
02-24-22
Russia
attacked...
Ukraine
responded ...
Russia
attacked...
Figure 1: Our pipeline for identifying and labeling narrative clusters from the daily publications of unreliable news websites.
have been difficult to uncover through manual, small-scale
investigations. We also discuss how having a continuous
tracking process can help analysts uncover and track the
most worrisome influence operations. We stress that our
approach does not make factual judgments on individual
stories or on the reliability of websites. Indeed, our sys-
tem takes as input websites that human experts previously
labeled as unreliable. Rather, our approach provides the
critical, real-time visibility into the spread of news narratives
online that human experts need to effectively identify and
respond to misinformation.
2. Background
Unreliable information often spreads through multiple
avenues as individual users, state-supported actors, and even
entire platforms participate in the dissemination of falsities.
Unreliable information can take the form of misinformation,
disinformation, fake-news, propaganda, among others [29].
Misinformation is any information that is false or inaccurate
regardless of the author’s intent [29]–[32]. The term “fake
news” is often used interchangeably with misinformation.
Disinformation, in contrast, is inaccurate information spread
with the deliberate purpose to mislead [29], [33]. Similar to
disinformation, propaganda refers to “deliberate, systematic
information campaigns, usually conducted through mass
media forms” regardless of whether the information is true
or false [29]. A single narrative can be considered disinfor-
mation when spread by a state actor and as misinformation
when spread by users. Individual websites can have mixtures
of misinformation, disinformation, propaganda, and true
information [34]. We refer readers to Jack et al. [29] for
a more detailed taxonomy.
3. Methodology
The goal of our work is to programmatically track how
narratives spread amongst “unreliable” news websites. In
this section, we define a narrative and then describe how we
collect news articles and extract narratives. We emphasize
that while we focus on websites known to publish mislead-
ing, false, or state-controlled narratives, we do not assume
that all narratives from these sites are “misinformation”.
Indeed, many stories are not [34]. We do not label new
narratives as “misinformation”, which is a qualitative, inves-
tigative task. As such, we refer to only individual stories that
have been previously identified by experts as misinformation
or disinformation, as false. We label the websites that spread
these verified false narratives as unreliable.
3.1. Narrative Definition
Tracking misinformation narratives requires a high de-
gree of specificity. Unlike traditional topic modeling, which
seeks to identify themes and/or statistical word correla-
tions [35]–[37], misinformation tracking requires distin-
guishing between specific narratives and stories. Within this
work, we define a narrative/story using the same definition
as the Event Registry [38], Hanley et al. [39], and Miranda
et al. [40]: collections of documents that seek to address
the same event or issue. For example, two example events
in the Event Registry are “Felix Baumgartner’s jump from
a helium balloon on October 14, 2012” and “bombings
during the Boston Marathon on April 15, 2013.” Within our
dataset, events constitute ideas like “election fraud in the
2020 US election” and “the COVID-19 vaccine leading to
mass death.” An example of two ideas—while related—that
we do not consider to be the same narrative are “US funds
Ukrainian War” and “Russia attacks Ukraine.”
3.2. System Architecture
As shown in Figure 1, our system (1) collects news
articles from unreliable news sites through web scraping on
a daily basis and from Common Crawl data [41]; (2) parses
out the news articles, extracting article text and segment-
ing articles into constituent passages; and (3) embeds text
passages into a shared subspace utilizing the large language

model MPNet [18]. To track the spread of narratives, our
system then (4) clusters semantically similar content using
DP-means, and (5) extracts keywords and generates sum-
maries of the clusters.
We opt for this LLM-based approach because our system
needs to track specific narratives. Prior approaches that
utilize simpler, more generic keyword-based topic modeling
tools like LDA fall short in identifying specific narratives
across different news websites [42]. Furthermore, keyword-
based approaches often rely on pre-existing expert knowl-
edge of disinformation campaigns and largely cannot adapt
to the rapid pace of the news ecosystem [43]. By utilizing
this new approach, our system can update and track news
stories without a priori or domain-specific knowledge in an
efficient and fine-grained manner.
For this paper, we use data from January 1 to November
1, 2022, but we emphasize that our system runs continu-
ously, enabling us to identify new narratives in near real
time. In the rest of this section, we detail each step of our
methodology and validate that our system captures specific
and coherent narratives.
3.3. Data Collection
Our study is based on scraping and parsing articles from
websites known to spread unreliable information.
Unreliable News Websites. We collect articles from
2,514 candidate websites that have been labeled as “po-
litically biased”, “misinformation”, “disinformation”, “con-
spiracy”, “fake news”, or “state-based propaganda” by past
studies (Iffy Index [44], OpenSources [45], Politifact [46],
Snopes [47], Melissa Zimdars [48], and Hanley et al. [49]).
This list includes politically-biased websites like daily-
wire.com, conspiracy-oriented websites like x22report.com,
and state-propaganda outlets like rt.com.
Scraping Articles. We crawl websites using Colly
1
and
Headless Chrome orchestrated with Python Selenium. For
each website, we collect the homepage and linked pages
daily from January 1 to November 1, 2022. To ensure full
coverage of each site’s published articles, we additionally
gather the HTML pages indexed by Common Crawl [50]
for each site during this same period. We emphasize that
under 1% of articles were found only in the Common
Crawl dataset, indicating that our scrapes found the vast
majority of published content on each site. We then parse
each HTML page to collect the published articles using
the Python libraries newspaper3k and htmldate. There
were several instances (e.g., sputniknews.com) where this
approach failed; in these cases, we built custom parsers
based on site-specific HTML elements.
Of our 2,514 candidate websites, 1,334 were operational
and published articles during our 2022 measurement period
(many sites that spread unreliable information are short-
lived [12], [51]). Altogether, we collect 1,915,449 articles.
We provide the URL data to researchers upon request.
1. https://github.com/gocolly/colly
GloVe BERT USE All-MPNet Our Model
0.580 0.464 0.749 0.840 0.856
TABLE 1: Evaluation–based on Pearson Correlation—of our
MPNet-contrastive model and other models on the SemEval STS-
benchmark [54]. Data for GloVe [55], BERT [56], the Universal
Sentence Encoder (USE) [57] is from Reimers et al. [58].
Figure 2: Evaluation of our model’s precision, recall, and F
1
scores
on the English portion of the SemEval22 dataset [61] (using 3.0 as
the cut-off for the two articles being about the same event [53]).
3.4. Preprocessing and Embedding
To prepare data for embedding, we first remove any non-
English articles using the Python langdetect library and
then remove URLs, emojis, and HTML tags. We then seg-
ment each article into its constituent paragraphs by splitting
article text based on newline and tab characters. Then, in line
with prior work, we subsequently divide these paragraphs
into 100-word article passages [39], [52], [53].
After preprocessing, we embed the constituent passages
that make up each article. Embedding passages rather than
entire articles is in line with prior work [52] for topic
analysis as articles often address multiple narratives but
embeddings should represent only a single narrative or
idea [39], [52], [53]. We thus embed passages to capture
context while also obtaining an embedding for the (often)
one narrative/idea present within the passage.
We specifically embed passages using a version of MP-
Net that we fine-tune on the semantic text similarity (STS)
task [39], [59] using unsupervised contrastive learning for
sentence embeddings as specified in Gao et al. [60] on a
random assortment of passages from January 2022 from
our websites. We perform this fine-tuning with the default
hyperparameters (learning rate 3 × 10
−5
, batch size=128,
and 1M examples) specified in Gao et al. and by freezing
all but the last two layers of a public version of MPNet.
2
See Appendix A for details. This ensures that our model
is attuned to the language present on our set of websites.
As seen in Table 1, despite not being trained on the Se-
mEval STS Benchmark [54], a benchmark for measuring the
quality of text embeddings, our model outperforms the fine-
tuned publicly released version of MPNet. After fine-tuning
our model, from the 1.9M articles, we embed 25,337,614
passages (10 hours on an Nvidia RTX A6000).
2. https://huggingface.co/sentence-transformers/all-mpnet-base-v2

0.45 Thresh. 0.50 Thresh. 0.55 Thresh. 0.60 Thresh.
80.6% ± 6.33% 85.7% ± 8.29% 94.7% ± 6.94% 96.29% ± 7.12%
TABLE 2: Evaluation of the precision of embedded messages hav-
ing the same narrative at various thresholds utilizing 2000 random
passages. We provide 95% Normal confidence intervals.
PASSAGE 1: The MaraLago search warrant served Monday was part of an ongoing Justice Department investigation
into the discovery of classified White House records recovered from Trump’s home earlier this year. The Archives
had asked the department to investigate after saying 15 boxes of records it retrieved from the estate included classified
records.
PASSAGE 2: The FBI raided Donald Trump’s estate in MaraLago using the pretext of Trump supposedly violating
the Presidential Records Act by keeping documents after he left office to initiate a siege to terrorize Joe Biden’s
chief political rival.
Figure 3: Passage pair at our selected similarity threshold (0.60).
3.5. Comparing Semantic Content
We compare the semantic content of our embeddings
utilizing cosine similarity [18]. Prior work [39], [62], [63]
has found that a cosine similarity threshold of 0.60–0.80
can be used to determine whether two pieces of text are
about the same topic. However, to ensure that we select a
minimum threshold that accurately models whether passages
are about the same narrative as defined in Section 2, we:
(1) benchmark our model on the English portion of the
Multilingual SemEval2022 dataset [61], and (2) manually
validate the coherency of a random sample of passage pairs.
As seen in Figure 2, on the SemEval22 [61] dataset,
as the similarity threshold increases, our model’s precision
in determining whether two passages are about the same
narrative increases while the corresponding recall decreases,
reaching a peak F
1
score near 0.60 cosine similarity.
To confirm this result, we perform a manual evaluation
by selecting 2,000 random passage pairs from our dataset
with similarities at varying thresholds and have two experts
determine whether the passage pairs are about the same
narrative (per our definition), determining the corresponding
precision at various thresholds. We calculate a Cohen’s
Kappa of 0.80 between our two raters, indicating a high
degree of agreement. As seen in Table 2, as the threshold
used to determine similarity increases, we see an increase in
precision. We choose a threshold of 0.60 (as a lower bound)
as it has acceptable manually calculated precision (96.29%)
and F
1
score on the SemEval22 [61] dataset (0.809). We
present an example passage pair at our selected threshold
of 0.60 in Figure 3 and at other thresholds in Appendix B.
3.6. Identifying Narratives
To identify narrative/stories in our dataset, we cluster
our passage embeddings using cosine similarity and DP-
Means, a non-parametric version of K-means (Appendix C).
Prior work has identified narratives using a similar high-
level approach [17], [39], but our methodology differs in
several ways based on our unique requirements. First, our
approach must be highly scalable. While Hanley et al. [39]
utilize a BERTopic-based method [64], we find that this does
not scale to the approximately 100K embeddings per day in
our dataset. Second, we need to update our clusters on a
daily basis as new news articles are published, which past
approaches like BERTopic do not allow. Third, since the
number of narratives is unknown a priori, the methodology
must automatically infer the number of clusters, which
precludes parametric algorithms like incremental K-means
clustering.
We specifically adapt Dinari et al.’s efficient and paral-
lelizable version of DP-Means [65] (Appendix C), making
four alterations. First, we cluster embeddings based on their
cosine similarity rather than their Euclidean distance. We
set λ = 0.60 (the minimum cosine distance an embedding
can be from a cluster before a new cluster is created) to
ensure that clusters have high semantic similarity, informed
by our prior manual investigation (Table 2). Second, we
perform partial fits over each day’s worth of news article
embeddings. Specifically, on each day throughout 2022, we
embed that day’s passages and update the previous day’s
cluster centers (i.e., we update our given clusters on a daily
basis with the DP-Means algorithm until convergence uti-
lizing that day’s article embeddings). Third, we remove the
random reinitialization of clusters added by Dinari et al. [65]
from the algorithm; we find that this step often led to
over-clustering given that many website passages are slight
variations of each other. Lastly, we note that rather than
relying on Dinari et al.’s released code, we re-implement
their algorithm to take advantage of the matrix multipli-
cation speedups that come from utilizing a GPU (3 times
speedup with an Nvidia RTX A6000).
For this work, we utilize the clusters from November 1,
2022. From January 1 to November 1, clustering all em-
beddings required the equivalent of 1.5 days. We filter out
clusters where 50% or more of the passages are from only
one website (e.g., author bios) or there were fewer than
25 articles to remove spam, similar to the methodology
specified by Leskovec et al. [17]. After this removal, we
identify 52,036 narrative clusters. Each article’s passages are
part of an average of 5.12 narrative clusters (4.0 median).
On average, each embedding has an average similarity of
0.688 to its cluster center, which shows that our embeddings
are assigned to clusters with high semantic similarity. Each
narrative cluster has an average cosine similarity of 0.016
with other identified narrative clusters, which indicates that
our approach identified distinct narratives.
3.7. Interpretability and Narrative Specificity
We create human-interpretable identities for our narra-
tive clusters using two approaches. First, we extract the most
distinctive and representative keywords of the cluster us-
ing pointwise mutual information [66], [67] (Appendix D).
Pointwise mutual information (PMI) is an information-
theoretic measure for discovering the associations amongst
different entities [67]. As in Kessler et al. [68], rather than
finding the pointwise mutual information between different
words, we utilize the measure to understand individual
words’ association with narrative clusters. In this manner,
we find the set of words most distinctive to/associated
with each cluster. Second, after identifying the top five
passages closest (i.e., with the largest cosine similarity) to

Passages
Narr. Keywords Checked Prec.
1 kiril, patriarch, orthodox, church, putin 427 99.53%
2 abbott, texas, border, greg, lone 500 99.40%
3 sinema, manchin, filibuster, kyrsten, senate 500 100.00%
4 hurricane, atlantic, storm, tropic, season 500 99.80%
5 balloon, leaflet, korea, korean, north 100 100.00%
6 monkeypox, york, nyc, outbreak, city 385 96.62%
7 johnson, resign, poll, boris, tory 500 95.20%
8 antibody, monoclon, regeneron, omicron, variant 302 100.00%
9 fauci, anthoni, kennedy, pharma, gate 384 100.00%
10 nucleic, acid, test, shanghai, province 500 99.40%
11 finland, sweden, nato, deploy, nuclear 133 100.00%
12 windfall, profit, tax, oil, barrell 379 99.21%
13 energy, europe, crisis, price, electric 500 100.0%
14 pen, macron, le, french, marin 500 99.20%
15 protein, spike, mrna, inject, cell 173 100.00%
Passages
Narr. Keywords Checked Prec.
16 peterson, suspend, rubin, jordan, elliot 252 100.00%
17 norwegian, ellingsen, feminist, lesbian, norway 108 100.00%
18 lantsman, trudeau, melissa, mp, swastika 127 100.00%
19 polio, 1979, eradicate, virus, disease 109 99.08%
20 humanitarian, aid, shelter, refuge, relief 500 100.00%
21 kiev, coup, nationalist, neonazi, nazi 143 98.60%
22 noah, flood, ark, wives, genesis 155 90.97%
23 fda, prescribe, offlabel, drug, treatment 195 100.00%
24 refugee, asylum, persecute, seeker, migrant 192 100.00%
25 swift, sanction, bank, sberbank, vtb 500 100.00%
26 orban, fidesz, viktor, hungary,victory 469 99.60%
27 unvaccined, infection, recipe, covid19, covid 167 100.00%
28 nuclear, closer, brink, cuban, war 364 96.43%
29 alexandra, pelosi, footage, nancy, daughter 100 100.00%
30 civilian, kabul, afghan, drone, strike 500 94.00%
Prec. 98.90%
TABLE 3: Evaluation of the precision of our narrative analysis model on a random set of 30 stories/narratives derived from the articles
in our dataset. Keywords were extracted utilizing pointwise mutual information. We checked all available passages in cases where there
are fewer than 500 passages in the story/narrative cluster.
the center of the cluster, we use an off-the-shelf state-of-the-
art BART [69] summarization tool from Huggingface fine-
tuned on news data to summarize the cluster. We utilize this
approach because while keywords provide an identifiable
“handle” for each cluster, keywords typically do not fully
capture the full semantic meaning or the specificity of our
narrative clusters. For example, the auto-generated summary
for the cluster with keywords Age, Pfizer, Booster, Children,
Vaccine is:
The U.S. Food and Drug Administration FDA in Octo-
ber 2021 authorized the PfizerBioNTech COVID vaccine
for children 5 through 11. Children under 5 remain the
only segment of the US population that isn’t eligible for
one of the COVID vaccines.
where a random passage from the cluster states:
As of now, U.S. children aged five and older are eligible
for the COVID19 vaccine, though only Pfizer’s shot has
received authorization. The Pfizer jab is also available
as a booster for children 12 and older.
However, the auto-generated summary for a similar cluster
with keywords Children, Risk, Adult, Covid, Immunity is:
Children have a minuscule risk of COVID mortality.
There is very limited safety data for vaccines from the
trials on children. If the risk of adverse reactions is the
same as for adults, the harms outweigh the risks.
where a random passage from the cluster states:
COVID poses no danger to children. They have a sta-
tistically zero chance of dying from that disease. The
COVID shots, however, are already linked to innumer-
able adverse reactions, and their longterm side effects
are unstudied.
This illustrates the need for further specificity using sum-
marization to understand the narratives being spread. We
provide several additional examples in Appendix F.
3.8. Validating Narrative Clusters
We evaluate our narrative clustering technique by vali-
dating whether a random sample of 500 passages (or max-
imum present) for a random set of 30 narrative clusters
are about the same narrative using the methodology out-
lined in Section 3.5. Our methodology identifies coherent
story/narrative clusters with an overall 98.9% precision and
a minimum precision of 90.97% for Topic 22 (Table 3).
3.9. Ethical Considerations
Our analysis is based on analyzing publicly posted news
articles. We limit the load that each news site experiences
by checking for new articles daily at a maximum rate of one
request every 10 seconds. We further follow the guidelines
as outlined by prior work for scraping data [5], [19]. The
hosts that we scan from are identifiable through WHOIS,
reverse DNS, and an HTTP landing page explaining how to
reach us if they would like to be removed from the study.
We received no requests from websites to opt-out.
3.10. Positionality Statement
The misinformation websites we study often covered
contentious political issues including election denial, the
Russo-Ukrainian War, and US abortion rights. As US-based
English-speaking researchers, we inevitably bring some bi-
ases to discussing these issues. We attempt to remain as neu-
tral as possible. We do not take any stance on political issues
and when labeling specific stories as being misinformation,
we rely fully on cited prior work from other researchers
and/or news groups.
4. Narratives on Unreliable News Sites
In the last section, we presented and validated our
methodology for programmatically extracting the narra-
tives promoted by unreliable news websites. Here, we
describe the most prolific narratives, trace three misin-
formation/propaganda stories, and derive communities of
topically-related websites.
4.1. The Largest Narratives
We start by analyzing the narratives most prolifically
covered by our set of unreliable news sites in 2022. As can

Narr. Keywords Articles Websites Most Profilic Domains Auto-Generated Summary
1 ukraine, troop, kyiv,
russian, donbas
9,579 378 express.co.uk (626),
southfront.org (523),
dailymail.co.uk (464)
The Russian military has not been able to fully encircle and neutralize the
grouping of Kyiv s forces in the Donbass so far. At the same time, the Russians
managed to liberate a number of important territories and towns.
2 zelensky, volodymyr,
ukraine, kyiv, president
8,705 392 dailymail.co.uk (548),
nypost.com (466), ex-
press.co.uk (411)
Ukrainian President Volodymyr Zelensky has accused Russian forces of com-
mitting genocide in his country. He also slammed the West.
3 index, consumer, infla-
tion, cpi, price
7,240 444 shorenewsnetwork.com
(963), theep-
ochtimes.com (514),
dailymail.co.uk (336)
The consumer price index climbed 0.6 percent from a month before. Compared
with January of last year, consumer prices are up 7.5 percent. The Consumer
Price Index increased 9.1 percent in the year through June.
4 musk, elon, twitter,
platform, tesla
7,196 335 nypost.com (364),
dailymail.co.uk (281),
theepochtimes.com
(222)
Tech Mogul and Tesla Boss Elon Musk is wellknown for his wisecracks and
witty posts he shares on Twitter. Musk has been critical of social media,
particularly Twitter, over its enforcement of rules that critics say targets
conservative voices.
5 germany, europe, oil,
sanction, energy
6,812 362 express.co.uk (355),
zerohedge.com (323),
rt.com (283)
Russia has been hit by sweeping sanctions on its economy and trade since
the start of Putin’s war in Ukraine. But measures by EU governments have
not targeted oil and gas contracts with Moscow. Europe is heavily reliant on
Russia for its energy needs.
TABLE 4: Top 5 narratives—by number of articles—in our 2022 dataset.
China recently staged livefire military drills in
the airspace and waters surrounding Taiwan
from August 4 to August 7. The action marked a
significant escalation in Beijing s military
actions toward the island nation and came in
direct response to a visit to Taipei
Tech Mogul and Tesla Boss Elon Musk is
wellknown for his wisecracks and witty
posts he shares on Twitter. Musk has
been critical of social media,
particularly Twitter, over its
enforcement of rules that critics say
targets conservative voice
The consumer price index
climbed 0.6 percent from a
month before, the
Department of Labor said
Thursday. Compared with
January of last year,
consumer prices are up 7.5
percent. Last week, the
Labor Department said the
consumer price
This is in tandem with educators growing obsession with
teaching sexual and gender identity curriculum to
students at as young of an age as possible. This gender
fluid indoctrination of children worldwide is a pedophile
push to justify pushing adult sexual thinking and
expressions
The Russian military has not been able to
fully encircle and neutralize the grouping of
Kyiv s forces in the Donbass so far. At the
same time, the Russians managed to liberate
a number of important territories and towns
We are on the precipice of a global food crisis.
The global food shortage is about to explode
into a fullblown crisis that will lead to pockets
of mass starvation and will even affect
firstworld countries around the globe.
The Supreme Court on
Friday overturned Roe v.
Wade, effectively ending
recognition of a
constitutional right to
abortion. This gives
individual states the
power to allow, limit, or
ban the practice
altogether.
On Monday evening, a draft opinion
document was leaked from the
Supreme Court in the United States
saying that the court has voted to
overturn Roe v Wade. In May,
Politico published a leaked draft of a
U.S. Supreme Court opinion
Former President Donald Trump said in a
statement Monday that his home at MaraLago
in Palm Beach, Florida, was "raided" by "a large
group of FBI agents" According to Trump, the
raiding agents even entered his personal safe
I suspect that leftists are
not fully opposed to the
idea of gun ownership as
they often pretend to be. I
think they would actually
like to retain their own
guns if possible, they just
don't want people like
you and I to have
White House press secretary
Jen Psaki issued a statement
following the press
conference attempting to
clean up Biden s mess. Psaki
addressed the situation in a
subsequent interview.
United States Customs and Border Patrol
reported a record 2.3 million migrant
encounters in the fiscal year 2022. The figure is
far higher when counting getaways and illegal
aliens who remain undetected.
Boris Johnson has been
told to resign by
Conservative party
members. Johnson was
facing pressure from
members of his own party
to resign.
Cases of inflammation of the heart
called myocarditis or pericarditis
have been reported very rarely after
both the Pfizer and Moderna
COVID19 vaccines. These cases have
been seen mostly in younger men
and within several days
China Covid19 Lockdowns Hit
Factories, Ports in Latest Knock
to Supply Chains. The prospect
of more Chinese supply logjams
is heightening fears that the
disruptions will ripple through
the global economy.
Figure 4: Article volume of popular narratives from January 1, 2022, to November 1, 2022.
be seen in Table 4, the most popular narratives concerned the
Russo-Ukrainian War, inflation, and Elon Musk’s criticism
and later acquisition of the social media platform Twitter.
As can be seen in Figure 4, we observe peaks in coverage
of specific stories, as well as narratives that maintained
consistent coverage throughout our study. For example,
stories about abortion peak both before the US Supreme
Court decision (Dobbs v. Jackson) about federal abortion
rights was leaked and following the official decision [70].
In contrast, a narrative about the EU’s role in NATO saw a
steady stream of articles throughout the year, with a slight
uptick following the Russian invasion of Ukraine. Analyzing
the specific news sites that post about each narrative, we
find that many Russian-backed and controlled websites [71]
such as rt.com and southfront.org, in addition to several
UK-based tabloids express.co.uk and dailymail.co.uk were
the most prolific in writing about the Russian invasion
of Ukraine (Narratives 1, 2, 5 in Table 4). This largely
matches previous studies of the Russian-controlled media
in influencing discussions on the war [39].
4.2. Misinformation/Propaganda Case Studies
As seen in the last section, many of the most common
narratives are mainstream news topics. However, one of our
goals is to track the spread of misinformation narratives.

In this section, we show that our technique is capable of
tracking known unreliable narratives by investigating the
evolution of one confirmed propaganda and two confirmed
misinformation stories.
Ukrainian Nazis (Keywords: Azov, Battalion, Regiment,
Far-right, Ukraine): One of the most prominent propaganda
narratives utilized by Russian media in justifying the Rus-
sian Federation’s invasion of Ukraine was that the Ukrainian
government was controlled by “neo-nazis” [66]. This is
despite Ukraine’s relatively low level of antisemitism [72].
Our method is able to find that even before the Russian
invasion of Ukraine on February 24, 2022, there were heavy
references to Nazism in Ukraine by Russian-controlled or
influenced outlets. For example, on January 27, gloablre-
search.ca penned:
3
If we are to draw parallels between the current crisis
on the Ukraine border and WW2 we should compare
the Neo-Nazi ideology which dominates Ukrainian na-
tionalism with that of Nazi Germany.
However, as seen in Figure 5, the major increase in the num-
ber of articles promoting this narrative occurred in the weeks
prior to the Russo-Ukrainian War (specifically jumping in
volume on February 8, 2022). The most prominent websites
that pushed this narrative were unsurprisingly known Rus-
sian propaganda outlets including globalresearch.ca (68 arti-
cles), sputniknews.com (55), and rt.com (46). Beyond these
known pro-Russian websites, we find US-based websites
like veteranstoday.com (64 articles), sott.net (62), and the-
gatewaypundit.com (21) repeating this narrative.
Killer Covid-19 Vaccines (Keywords: Vaccine, Safe, Ad-
verse, MRNA, Effect): One prominent misinformation nar-
rative about COVID-19 that we identify is that COVID-19
vaccines are “killer vaccines” and a major cause of death
around the world. For example on lewrockwell.com, an
author wrote:
4
Whatever they may be, these vaccines are most definitely
not safe. We can very clearly see this from the explo-
sion of reports of death to the Vaccine Adverse Event
Reporting System (VAERS), which coincided with the
introduction of the Covid injections in late 2020.
As seen in Figure 5, stories about “killer vaccines” have
remained prominent throughout 2022, increasing in popu-
larity several times throughout the year. The sites that most
prominently echoed this narrative were theepochtimes.com
(53 articles), pandemic.news (36), and vaccines.news (31).
This is consistent with prior studies [73], [74].
2020 Election Denialism (Keywords: Fraud, Election, 2020,
Irregular, Voter): The narrative that the presidential elec-
tion was stolen and that current President Biden is illegit-
imate [75] spread throughout social media and was a key
3. https://web.archive.org/web/20220127162858/https://
www.globalresearch.ca/war-fever-air-west-confuses-russia-nazi-germany/
5768335
4. https://web.archive.org/web/20220120061509/https://
www.lewrockwell.com/2022/01/vasko-kohlmayer/dangerous-and-deadly-
over-1000-scientific-studies-referencing-injuries-and-deaths-from-covid-
vaccines/
The Azov Regiment is reviled by Putin
s Kremlin as a band of Russia-hating
neo-Nazis. The battalion denies
allegations of fascism, Nazism and
racism and says Ukrainians from
various backgrounds serve in Azov.
There is no evidence the
new vaccines are safe,
while there is limited
evidence that they may
be more harmful than
earlier COVID19
vaccines. In the absence
of human testing, there
is no way to truly predict
their safety.
Voting fraud is real . And there was a lot
of it in the 2020 election. Since 2020, the
election system in the United States has
been plagued with overwhelming reports
of fraud on almost every level.
Figure 5: Volume over time for case-study narratives of Ukrainian
Nazis, Killer COVID-19 vaccines, and 2020 Election Denialism.
aspect of the January 6, 2021 attack on the US Capitol [5].
We see in our dataset that this false narrative maintained
a substantial presence amongst unreliable news sites (Fig-
ure 5). For example, the fringe website thetrumpet.com
wrote on January 6, 2022:
5
The insurrection hoax is a cover-up for the stolen
election
The websites that most prominently repeated this narra-
tive were welovetrump.com (143 articles), thegatewaypun-
dit.com (55), and votefraud.news (14).
4.3. Communities of Unreliable News Websites
To begin to capture the semantic communities that exist
within the unreliable news ecosystem, we utilize each web-
site’s distinct distribution of articles among our discovered
set of 52,036 stories/narratives. To compare each website’s
reporting choices and semantic content, we represent each
website’s narratives as a multinomial distribution. For ex-
ample, if we had three narratives (rather than 52.0K) and
a website that wrote five articles about Narrative 1, four
articles about Narrative 2, and one article about Narrative
3, the website’s distribution would be [0.5, 0.4, 0.1]. We
do this for all 52,036 narratives and 1,334 websites, thus
representing each website as a 52,036-dimensional vector of
probabilities. We then use Jensen-Shannon Divergence [76]
(detailed in Appendix E) to compare websites’ probabil-
ity vectors. For example, the JS-Divergence of rt.com and
sputniknews.com.com, two Russian state-sponsored web-
sites [39], [71] is 0.412 while the JS-Divergence of rt.com
and nypost.com, a US-based website, is 0.605.
After calculating each website’s narrative similarities
using JS-Divergence with every other website in our dataset,
we build an undirected graph with edge weights based on
these values (i.e., an edge between a website P and Q is
given a weight of 1 − JS(P ||Q)) where JS(P ||Q) is the
JS-Digerence between websites P and Q. We determine
communities of websites using the Louvain clustering al-
gorithm [77]. Louvain clustering identified 3 communities,
5. https://web.archive.org/web/20220107091002/https://
www.thetrumpet.com/stephen-flurry/25070-the-insurrection-hoax-is-
a-cover-up-for-the-stolen-election
and from these communities, we qualitatively identified
the corresponding three semantic communities: US-focused,
International, and Conspiratorial. We label these clusters
based on the top topics found within each cluster, with the
US-focused cluster writing about Abortion and the Biden
Administration, the International cluster about the Russo-
Ukrainian War, and the Conspiratorial cluster heavily writ-
ing about COV1D-19 vaccines.
US-focused Community. 696 websites fall into our US-
focused community including sites like dailywire.com, bre-
itbart.com, and welovetrump.com. The most common nar-
rative in the community concerned the US Supreme Court
Dobbs v. Jackson decision to overturn the 1973 Roe v. Wade
decision that provided the federal right to abortion (Key-
words: Roe, Abortion, Wade, Overturn, 1973). To further
examine the role of this website community, particularly in
regard to its most prominent narrative, we collect a larger set
of narratives that more broadly relate to the topic of abortion
by aggregating all 121 narrative clusters whose centers have
a 0.50 similarity to the Abortion/Roe cluster.
We consider a website to originate a narrative if they
published an article about the narrative on the first day
that the narrative appeared in our dataset (more than one
website can originate a narrative). Altogether, we find that
66.1% of Roe/Abortion narratives originated from this com-
munity, with the website rawstory.com originating the most
Roe/Abortion narratives (24). In addition to originating most
of the narratives about abortion, these websites contributed
77.0% of the articles on the 121 narratives about abor-
tion; theepochtimes.com (1,330 articles) and breitbart.com
(1,264 articles) had the most. Largely expected, many In-
ternational websites such as dailymail.co.uk (1,104 articles)
and Conspiratorial websites like evil.news (65 articles) also
picked up on these US-centered political narratives, evidenc-
ing the spread of stories from this community.
International Community. 405 websites fall into our In-
ternational community including rt.com and dailymail.co.uk.
The top story was one of our top overall narratives: the Rus-
sian invasion of Ukraine (Keywords: Ukraine, Kyiv, Troop,
Russian, Donbas). We gather a larger set of 432 narrative
clusters that discuss the Russo-Ukrainian War using the
same methodology outlined in the prior section.
We find that 42.4% of Russo-Ukrainian War narra-
tives started from the International community of websites
with 4.6% of these narratives specifically starting on nine
pro-Russian propaganda websites [71]. Globalresearch.ca
(19 narratives, tt.com (9 Ukraine narratives) and tass.com
(10 Ukraine narratives) originate the most narratives among
these Russian websites. We again find that this cluster
of websites is responsible for a large portion (56.12%)
of articles about the war. Again, largely expected, other
websites such as nypost.com (2,934 articles) or treason.news
(32 articles) write extensively about the conflict as well.
Conspiratorial Community. 233 websites belong to our
Conspiratorial community, including popular sites known
for spreading conspiracy theories about QAnon and COVID-
19 [5], [49] like unz.com, qresear.ch, and radiopatriot.net.
Unsurprisingly, the top narrative within this community con-
cerns COVID-19 (Keywords: Children, Risk, Adult, Covid,
Immunity). We gather a more extensive set of narrative clus-
ters that discuss the COVID-19 and/or COVID-19 vaccines
using the same methodology outlined before; altogether
gathering 146 narratives. Most prominently, the website
childrenshealthdefense.org, the nonprofit run by Robert F.
Kennedy Jr., wrote about nearly every COVID-19 story in
our dataset (1,774 articles).
We find that our set of Conspiratorial websites originate
38.3% of narratives about COVID-19, the most prominent
of these being nvic.org (15 COVID narratives) and covidref-
erence.com (11 COVID narratives). We note that COVID-19
narratives originated not only from these websites but from
our International (28.0%) and US-focused cluster (33.3%)
as well. However, despite this, we find that this cluster is
only responsible for 17.8% of the articles about COVID-19.
This shows that COVID-19 narratives came from multiple
sources and spread throughout the misinformation news
ecosystem.
5. Originating and Amplifying Narratives
As seen throughout the last section, several websites play
dominant roles in perpetuating and promoting certain types
of stories. In this section, we identify and quantify which
websites have pivotal roles in originating and amplifying
narratives throughout the ecosystem of unreliable websites.
As before, we consider a website to originate a narrative if it
published an article about the narrative on the first day that
the narrative appeared in our dataset (more than one website
can originate a narrative). We consider a website to have
amplified (i.e., increased the popularity of) a narrative if it
(1) posted an article about the narrative before the narrative
peaked in popularity, (2) did not originate the narrative, and
(3) if the posted article appeared in the first 15% of the
total volume of that given narrative. We utilize the 15%
cutoff as it ensures that the vast majority of a narrative’s
articles have not been published yet (i.e., the story has not
dramatically increased in popularity already), allowing us to
observe how amplification affects the narrative’s popularity.
This threshold is consistent with prior work [17].
With this approach, we investigate how the popularity
of a website influences its effectiveness in originating and
amplifying narratives using website rank data provided by
the Google Chrome User Report (CrUX) from October
2022, which Ruth et al. showed to be the most reliable
website popularity metric [78].
5.1. Originating Narratives
To measure the efficacy of websites in originating narra-
tives, we perform a correlational comparison of the number
of external non-origin articles that are written about a given
narrative in the week after a given website originated a
narrative vs. the number of non-origin external articles that
are written in the week after origination if the website did
not originate the narrative but still eventually wrote about

CrUX Wtd. Ext. Cohen’s To Peak Cohen’s
Domain Rank Art.∆ D ∆ (Days) D
dailymail.co.uk < 1K 0.301 0.679 -20.23 -0.376
express.co.uk < 1K 0.161 -0.026
∗
-7.86 0.040
∗
breitbart.com 1K–5K 0.388 1.075 -54.89 -0.877
nypost.com 1K–5K 0.362 0.819 -45.47 -0.736
zerohedge.com 1K–5K 0.180 0.628 -34.18 -0.614
thegatewaypundit.com 5K–10K 0.300 1.045 -62.32 -0.980
newsmax.com 5K–10K 0.306 0.832 -32.58 -0.690
dailystar.co.uk 5K–10K 0.193 0.213
∗
-41.12 -0.540
redstate.com 10K–50K 0.502 1.413 -69.0 -1.129
twitchy.com 10K–50K 0.454 1.390 -71.89 -1.318
dailywire.com 10K–50K 0.453 1.345 -73.45 -1.316
theconservativetreehouse.com 50K–100K 0.628 1.969 -79.13 -1.612
halturnerradioshow.com 50K–100K 0.475 1.578 -51.22 -0.987
justthenews.com 50K–100K 0.811 1.206 -71.62 -1.218
– – – – – –
CrUX Wtd. Ext. Cohen’s To Peak Cohen’s
Domain Rank Art.∆ D ∆ (Days) D
therightscoop.com 100K–500K 0.684 1.758 -82.53 -1.791
weaselzippers.us 100K–500K 0.674 1.519 -81.88 1.786
∗
toddstarnes.com 100K–500K 0.576 1.475 -70.96 -1.434
nationalfile.com 500K–1M 0.406 1.306 -70.21 -1.341
gellerreport.com 500K–1M 0.359 1.259 -141.96 -2.279
∗
ussanews.com 500K–1M 0.300 1.238 -121.92 -2.567
infostormer.com 1M–5M 0.763 2.514 -154.65 -4.212
projectveritas.com 1M–5M 0.617 2.112 -62.98 -1.199
pacificpundit.com 1M–5M 0.711 1.711 -11.10 -2.139
anonhq.com 5M–10M 1.152 1.614 -93.18 -2.703
redstatenation.com 5M–10M 0.502 1.219 -71.13 -1.218
thejeffreylord.com 5M–10M 0.554 1.185 -61.55 -1.133
thefreedomtimes.com 10M–50M 0.530 1.610 -58.44 -1.174
presscorp.org 10M–50M 0.554 1.460 -85.46 -1.462
trueviralnews.com 10M–50M 0.218 0.598 -52.85 -0.746
TABLE 5: We present the weighted average change (and effect-sizes) in the number of external articles that are published by a random
subset of 100 external domains in the week after the website publishes the narrative (i.e., articles not written by the origin domain)
and the average change in time (and effect-sizes) for a story to peak in popularity when a website originates a narrative. We utilize
the Mann-Whitney U-test for significant differences in the means. After applying the Bonferroni correction, we conclude that a value is
significant if the p-value is < 0.0017 (i.e., 0.05/29). We star values that are not significant.
CrUX Wtd. Ext. Cohen’s To Peak Cohen’s
Domain Rank Art.∆ D ∆ (Days) D
dailymail.co.uk < 1K 0.626 1.546 -14.59 -0.102
express.co.uk < 1K 0.513 0.745 -16.52 -0.187
breitbart.com 1K–5K 0.821 1.726 -21.73 -0.176
nypost.com 1K–5K 0.739 1.617 -16.55 -0.076
zerohedge.com 1K–5K 0.531 1.188 -28.57 -0.291
thegatewaypundit.com 5K–10K 0.754 1.519 -23.13 -0.192
newsmax.com 5K–10K 0.649 1.331 -25.75 -0.261
rawstory.com 5K–10K 0.540 1.080 -16.03 -0.192
redstate.com 10K–50K 0.657 1.955 -21.22 -0.171
babylonbee.com 10K–50K 1.726 1.750 -31.20 -0.380
∗
twitchy.com 10K–50K 1.111 1.698 -18.52 -0.095
rumormillnews.com 50K–100K 1.427 2.035 -17.12 0.164
∗
beforeitsnews.com 50K–100K 0.894 1.989 -32.46 -0.312
brighteon.com 50K–100K 0.520 1.700 -40.79 -0.479
– –
CrUX Wtd. Ext. Cohen’s To Peak Cohen’s
Domain Rank Art.∆ D ∆ (Days) D
populistpress.com 100K–500K 1.425 1.861 -43.32 -0.389
∗
henrymakow.com 100K–500K 1.148 1.831 -17.18 -0.190
∗
sgtreport.com 100K–500K 0.593 1.739 -27.24 -0.320
ussanews.com 500K–1M 0.972 2.084 -9.08 -0.113
politicalflare.com 500K–1M 2.011 1.917 -1.86 -0.022
∗
yournews.com 500K–1M 1.064 1.762 -39.37 -0.434
americafirstreport.com 1M–5M 0.611 2.406 -16.84 -0.157
survivethenews.com 1M–5M 0.897 1.890 -26.40 -0.260
barenakedislam.com 1M–5M 1.518 1.670 -32.95 -0.207
patriotjournal.org 5M–10M 1.129 1.864 -15.68 -0.064
∗
legitgov.org 5M–10M 1.156 1.530 -26.13 -0.263
∗
gopdailybrief.com 5M–10M 0.813 1.444 -31.51 -0.377
roguereview.net 10M–50M 0.976 1.378 -20.78 -0.222
∗
trueviralnews.com 10M–50M 0.815 1.310 -27.59 -0.315
thefreedomtimes.com 10M–50M 0.641 1.187 -14.31 -0.006
∗
TABLE 6: e present the weighted average change (and effect-sizes) in the external articles that are published by a random subset of 100
external domains for a given domain’s amplified narratives (i.e., articles not written by the origin domain) and the average change in
time (and effect-sizes) for a story to peak in popularity when a website amplifies a narrative. We utilize the Mann-Whitney U-test for
significant differences in the means. After applying the Bonferroni correction, we conclude that a value is significant if the p-value is
< 0.0017 (i.e., 0.05/29). We star values that are not significant.
that narrative. We note that for this analysis, we weight the
number of articles by the log inverse of its CrUX popularity
ranking [79], [80] to ensure that we do not consider an
article from a highly popular website such as breitbart.com
the same as from a relatively obscure website such as
welovetrump.com.
To ensure each website has a marked effect on the full
unreliable news ecosystem and to improve the robustness
of our approach, we utilize a bootstrapping procedure [81]
(B = 250) to measure the influence of each website by
taking a random subset of 100 websites in each bootstrap
and then measuring the weighted increase in the number
of articles across this set of a random set of 100 websites.
We provide the average effect size (Cohen’s D)/statistical
measure of the increase in articles and the p-value to check
for the significance (using Mann-Whitey U-tests) for the
change in the number of external articles in Table 5. For this
section, we limit our analysis to websites that consistently
originate articles by only considering websites with at least
25 instances of originating an article.
We observe only a small correlation (Pearson correlation
ρ = 0.229) between a website’s popularity and its ability to
originate and perpetuate narratives amongst other unreliable
news websites. For example, considering express.co.uk and
dailymail.co.uk, two tabloids known to engage in sensation-
alism and biased reporting with the highest CrUX popular-
ities, while dailymail.co.uk is fairly effective at originating
narratives (Cohen’s D = 0.679), express.co.uk is one of the
worst at originating new narratives (Cohen’s D = -0.026).
Further, a seemingly unpopular website, infostormer.com,
is one of the best at propagating narratives it originates to
other sites. This illustrates many different types of websites
can originate and propagate narratives in the misinformation
news ecosystem. Infostormer.com, with a header labeled
the “Jewish Problem”, writes heavily sensationalist and
antisemitic perspectives on the news that is taken up by other
websites. For example, after writing an article on how the
CNBC news host Jim Cramer was promoting Meta stock,
6
this news story was later covered by more popular websites
like activistpost.com
7
and hannity.com.
8
In addition to quantifying each website’s efficacy in orig-
inating narratives, we determine how quickly after a website
originates a narrative that the story peaks in popularity.
Here, a negative Cohen’s D indicates that the “time for
6. http://web.archive.org/web/20221028232854/https://infostormer.com/
jew-jim-cramer-cries-and-apologizes-for-hyping-metas-stock/
7. https://web.archive.org/web/20221028014725/https://
www.activistpost.com/2022/10/the-big-tech-companies-are-telling-us-
exactly-where-the-economy-is-headed-in-2023.html
8. http://web.archive.org/web/20220901000000*/https://hannity.com/
media-room/sad-money-jim-cramer-in-tears-after-meta-stock-nosedives-
i-made-a-mistake/
a narrative to peak” occurs faster. This metric, combined
with the previous metric, describes how effective a website
is at reorienting online conversations to its own narratives.
We see only a slight correlation (ρ = 0.164) with a web-
site’s CrUX-defined popularity. Rather, we again see that
several small websites are highly effective in originating
narratives that peak quickly (i.e., writing about narratives
that become of immediate interest). For example, when the
small website infostormer.com originates narratives, those
narratives peak in popularity 155 days earlier than when
infostormer.com does not originate narratives (Table 5).
We similarly observe that the right-wing and conspiratorial
websites ussanews.com and gellerreport.com, which often
wrote about QAnon [5] are also highly effective at quickly
landing their narratives on other websites, with some of the
lowest “time to peak” in our dataset.
5.2. Amplifying Narratives
To understand how effective websites are at amplify-
ing narratives, we correlationally compare the number of
external non-origin articles that are written about a given
narrative when a given website amplifies the narrative versus
when the website does not amplify the narrative but still
eventually wrote about that narrative. We utilize the same
weighting and bootstrapping procedure as in the previous
section, again limiting our analysis to websites that am-
plify at least 25 narratives across our period of study. We
again observe only a slight correlation between a website’s
popularity and its ability to amplify narratives (Pearson
correlation ρ = 0.302). As before, we see in Table 6 that
websites across different CrUX popularities excel at am-
plifying narratives. For example, One of the most effective
websites is barenakedislam.com, an anti-Islam website with
the slogan “It isn’t Islamaphobia when they really ARE
trying to kill you.” For example, after echoing a narrative
about how Muslim men were targeting Ukrainian refugees,
9
this news story traveled to an additional 12 other unreli-
able news websites including more popular websites like
americanthinker.com
10
and breitbart.com.
11
This illustrates
how different types of websites can amplify and propagate
narratives in the misinformation news ecosystem.
Finally, we determine the effect of narrative amplifica-
tion by each website on how quickly the narrative peaks.
There is again a small correlation between website pop-
ularity and amplification (Pearson correlation ρ = 0.152).
As seen in Table 6, the most effective website at quickly
amplifying narratives to their peak popularity is populist-
press.com, a drudge-style news website that hosts hyperlinks
9. https://web.archive.org/web/20220422091130/https://
barenakedislam.com/2022/03/21/what-a-surprise-not-ukrainian-female-
refugees-say-they-dont-feel-safe-in-multicultural-sweden/
10. http://web.archive.org/web/20220619083901/https://
www.americanthinker.com/articles/2022/06/the
only rape where the
left says victimblaming is okay.html
11. https://web.archive.org/web/20220527122734/https://
www.breitbart.com/europe/2022/05/27/sweden-asylum-home-tells-
ukrainian-women-dress-modestly-to-not-provoke-migrant-men/
Figure 6: Time lag for differently ranked websites. The most
popular websites write more of their articles prior to the peak of
a narrative’s popularity. In contrast, less popular websites tend to
respond to narratives and write most of their articles after the peak.
Social Media Posts With Corresponding
Platform Posts News Article Narrative
8kun.top 632,091 34,959 (5.53%)
4chan.org 4,690,669 450,027 (9.59%)
TABLE 7: Our dataset of social media posts and their relationship
to the narratives published by unreliable news websites.
to different news articles. Despite not hosting many articles
itself, we see that when it does mention a narrative, this news
story is more likely to more quickly peak in popularity.
Trend Setting. Despite not seeing clear discernible patterns
in how website popularity correlates with a website’s ability
to originate and amplify narratives, we do observe differ-
ences in when these websites write about given narratives.
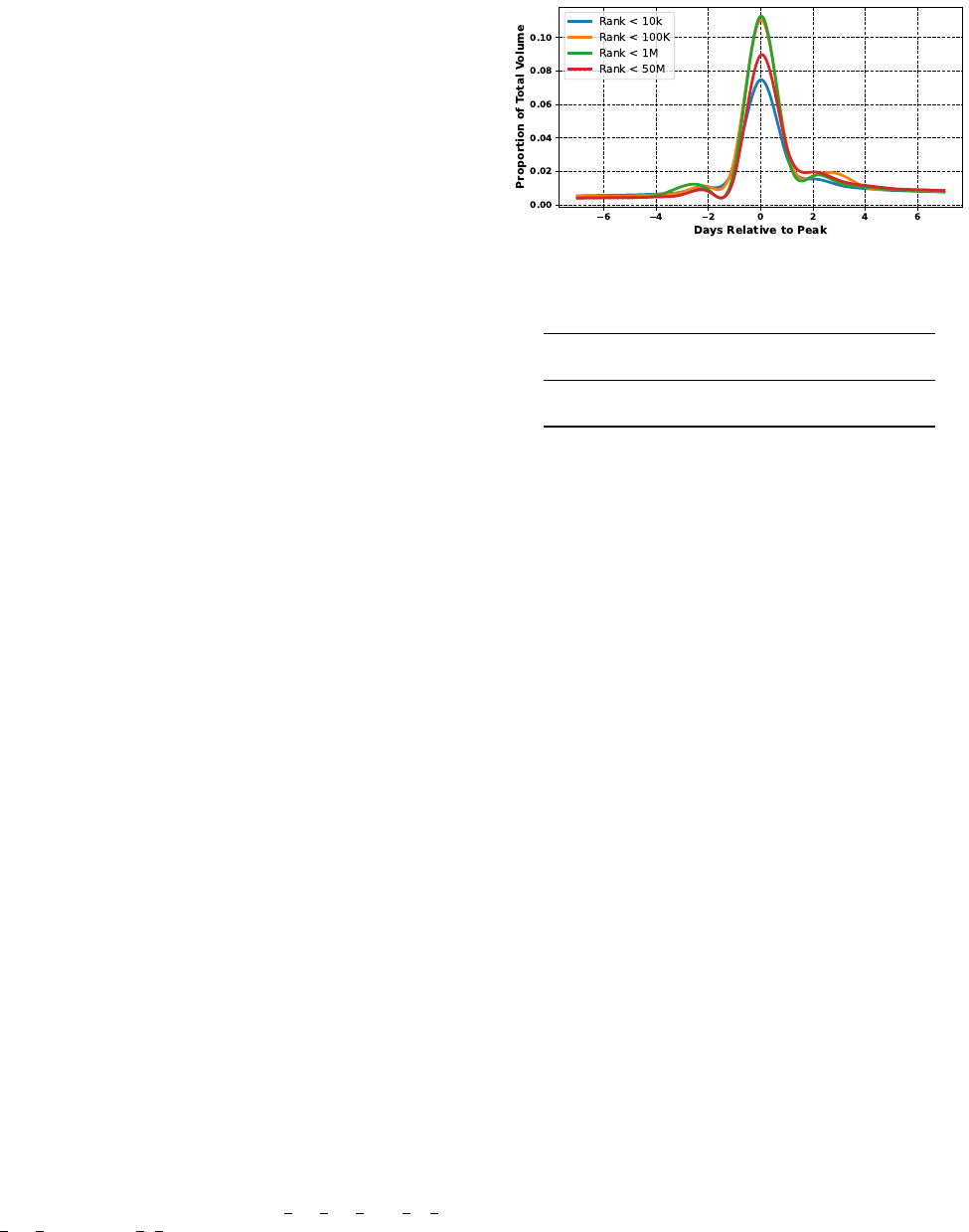
As seen in Figure 6, across all narratives, more popular
websites tend to write fewer articles (as a proportion) on the
day that a given narrative peaks. A slightly higher percentage
(37.37%) of articles from websites with a CrUX rank <10K
come before the peak versus the 31.39% of articles with a
rank above 1M. This indicates, as also found by Leskovec
et al. [17], popular websites have some ability to set the
agenda for the topic smaller websites write.
5.3. The Role of Fringe Forums/Social Media
We now analyze the relationship between our set of
unreliable news websites and the fringe social media sites
8kun and 4chan. As with our set of unreliable news websites,
we scrape 8kun and 4chan /pol posts published between
January 1 and November 1, 2022 (Section 3.4). 8kun data
is readily available on their website 8kun.top; 4chan /pol
posts are archived through the website archive.4plebs.org.
Altogether, we gather 632,091 posts from 8kun.top and
4.69 million posts from 4chan (Table 7).
To find the correspondence of 8kun and 4chan comments
between news narratives, we preprocess, embed, and assign
each 8kun post to its most similar narrative cluster. As
before, we utilize a threshold of 0.60 for matching a com-
ment to its corresponding news article narrative. Altogether,
we find that 34,959 (5.53%) of comments on 8kun.top and
450,027 (9.59%) of comments from 4chan.org correspond to
a narrative on our set of unreliable news websites (Table 7).

Top Narratives on 8kun Comments
ukraine, nato, putin, russia, war 625
hillary, collusion, clinton, mueller, lie 454
antisemit, jew, israel, zionist, israel 373
trucker, trudeau, canadian, ottawa, convoy 365
ukraine, kyiv, troop, russia, donbas 286
Top Narratives on 4chan Comments
ukraine, kyiv, troop, russia, donbas 4,361
volodymyr, zelenskyy, ukrainie, kyiv, president 3,003
ukraine, conflict, war, escalation, tension 2,792
race, white, theory, black, crt 2,134
jew, white, supremacy, goyim, zionist 2,079
TABLE 8: The top topics from our set of unreliable news websites
present on 8kun and 4chan /pol.
Narratives Wtd. Ext. Cohen’s To Peak Cohen’s
Platform Originated Art.∆ D ∆ (Days) D
8kun 392 0.400 1.759 -73.92 -1.117
4chan 2, 455 0.394 0.842 -29.45 -0.434
Narratives Wtd. Ext. Cohen’s To Peak Cohen’s
Platform Amplified Art.∆ D ∆ (Days) D
8kun 2, 728 0.760 0.283 -19.82 -0.353
4chan 12, 164 0.327 0.913 1.19 0.017
∗
JS-Sim.
Platform to News Most Similar News Sites
8kun 0.240 lucianne.com, radiopatriot.net, americanthinker.com
4chan 0.248 unz.com, beforeitsnews.com, thetruthseeker.co.uk
TABLE 9: The influence of 8kun and 4chan on the ecosystem of
unreliable news websites and their similarity (by JS-Divergence)
to the unreliable news dataset. We star values were not found to
be significant according to the Mann-Whitney U-test.
5.3.1. 8kun. Examining the top narratives posted on 8kun
that correspond with a news narrative (Table 8), we see that
the most commonly shared narratives on 8kun.top concern
the Russo-Ukrainian war, the investigation of Donald Trump
by Special Counsel Robert Mueller [82], antisemitic beliefs,
and the 2022 Trucker Convoy in Ottawa Canada [83]. This
largely corresponds with 8kun being known as the home
of hard-right, conspiratorial, and antisemitic posts [84]. As
in Section 4.3, we determine the distribution of narratives
from our set of unreliable websites that are present on
8kun to understand the similarity between 8kun and the
collective narratives on our set of unreliable news websites.
Altogether, 8kun has a JS-Divergence of 0.240 with the
collective narrative distribution of unreliable news websites
(Table 9). Performing this on an individual site level, we ob-
serve several of the websites with the most similar narrative
distributions prominently discuss conspiratorial ideas (e.g.,
lucianne.com and radiotpatriot.net) [5]. Having examined
similarities between the narratives discussed on 8kun and
those on particular websites in our dataset, we next deter-
mine the influence of 8kun on our unreliable news website
ecosystem. We utilize the same definitions of originate and
amplify as well as the same methodology as in Sections 5.1
and 5.2. As seen in Table 9, 8kun originating or amplifying
a particular narrative has a modest effect on the number of
articles written about that narrative. In the week after 8kun
originates a given narrative, we see an average Cohen’s D
of 1.759. In contrast, in the week after 8kun users amplify
a narrative, we observe a Cohen’s D of 0.283, illustrating
that 8kun is somewhat better at originating narratives than
amplifying narratives. Thus, while not as effective as some
of the websites in our dataset (Tables 5 and 6), when 8kun
users comment on narratives, this correlates with a slight
increase in the narrative’s popularity. We see this further
mirrored in the effect that 8kun has in expediting narratives
to peak earlier. On average, if 8kun originates a narrative,
it peaks in popularity 73.9 days earlier than if 8kun did
not originate the narrative. Similarly, if 8kun amplifies a
narrative it peaks in popularity 19.8 days earlier on average.
5.3.2. 4chan /pol. Looking at the top corresponding shared
narratives on 4chan /pol, we see several that target Judaism
and the Jewish people (Table 8). As with 8kun, 4chan has a
reputation for antisemitism and racist language. Besides the
narratives that center on the Russo-Ukrainian war, we see
this racism and antisemitism reflected in the top shared nar-
ratives on the website [85]. Determining the distribution of
narratives from our set of unreliable news websites that are
present on 4chan, altogether, 4chan has a JS-Divergence of
0.248 with the collective narrative distribution of unreliable
news websites (Table 9). Examining the most similar web-
sites to 4chan, we observe several with known conspiratorial
reputations. As documented by Medias-Bias/FactCheck, the
most similar website to 4chan, unz.com is a conspiratorial
and hate-oriented website that often cites white nationalist
groups in its articles [86]. Similarly, beforeitsnews.com [87]
and thetruthseeker.co.uk [88] are known to “promote con-
spiracy theories and pseudoscience.”
Finally, we determine the role 4chan has in promoting
and amplifying narratives within our ecosystem of unreliable
news websites. We observe a similar effect to 8kun, in terms
of the weighted increase of articles when 4chan originates
a narrative compared to when it does not (Cohen’s D of
0.438). However, unlike 8kun, we do observe that 4chan
is better at amplifying narratives, with an effect size of
Cohen’s D of 0.913 (Table 9). However, in contrast to 8kun,
4chan is relatively less effective at getting the narrative to
peak earlier. If 4chan users originate a narrative, it peaks in
popularity 29.5 days earlier compared to 73.9 days earlier
when 8kun originates a narrative. When 4chan amplifies a
narrative, it has little effect on when that narrative peaks.
6. Detecting Narratives and Fact-Checking
In the last two sections, we analyzed the narratives and
behavior of unreliable news websites during 2022. In this
section, we present two case studies that highlight how our
programmatic approach can also identify new narratives and
assist in focusing fact-checking efforts.
6.1. Identifying New Trending Narratives
By examining the week-over-week percentage increases
in story volumes, we programmatically determine which
narratives are receiving new or renewed focus on unreli-
able news websites, which is imperative for ameliorating

the spread of specious information [9]–[11]. The narratives
that increased most in volume during the last week of our
experiment (October 26 to November 1, 2022) were:
The Attack of Paul Pelosi, Keywords: Pelosi, Depap,
hammer, Nancy, Paul. On October 28, 2022, the hus-
band of Congresswoman Nancy Pelosi was attacked in his
home [89]. Largely due to the proximity of the time of the
attack to the 2022 US midterm elections, the attack became
a source of conspiracy theories and wild speculation. For
example, one user wrote on thegatewaypundit.com:
12
Whenever bad things happen to Paulie P, his wife
always manages to have an alibi.
364 articles (compared to zero the week before) were written
about the event within our dataset across 175 websites. The
thegatewaypundit.com had 44 articles, dailymail.co.uk.com
had 40, and nypost.com had 37.
The Seoul Halloween Stampede, Keywords: Halloween,
Seoul, Itaewon, Festivity, Stampede. On October 29, 2022,
a crowd rush in the Seoul neighborhood of Itaewon resulted
in the death of 158 people. Across our dataset, we see
132 articles across 46 websites written about this event,
with 18 articles from dailymail.co.uk, 11 from republic-
world.com, and 8 from mirror.co.uk.
Elon Musk’s First Visit to Twitter Headquarters, Key-
words: Sink, Headquarters, Musk, Carry, Twitter. After
officially purchasing the social media company Twitter, on
his first visit to the company on October 26, Elon Musk car-
ried a sink into the headquarters with him. This prop humor
by Musk was supposed to be a play on “let that sink in” but
with a real sink. We see 176 articles from 84 domains about
the story, with 10 articles from the dailymail.co.uk, 9 from
westernjournal.com, and 8 from conservativeangle.com.
6.2. Fact-Checking
One approach to combating the spread of new misin-
formation stories that many organizations have adopted is
fact-checking. Fact-checking a story requires hours to deeply
understand its context and nuance [90]. Unfortunately, this
means that propaganda and misinformation often spread
widely in a rapidly evolving media landscape before jour-
nalists can respond. Our approach can serve as a way to
programmatically identify new misinformation narratives as
they appear and begin to gain traction, ideally reducing the
amount of time from when a story is published to when a
fact-checker can respond.
To show how our system might be useful to fact-
checking organizations, we utilize our approach to analyze
the behaviors of particular narratives before being fact-
checked by three organizations: Politifact, Reuters, and AP-
News [91]–[93]. For the three agencies, we gathered the
set of fact-checking articles that each published in 2022.
Altogether we scraped 1,524, 3,090, and 140 articles from
12. https://web.archive.org/web/20221028130434/https://
www.thegatewaypundit.com/2022/10/breaking-pelosis-home-broken-
early-morning-san-francisco-paul-pelosi-violently-beaten-taken-hospital/
Narr. Med. Med. Med.
Fact- Art. Prior Days to Days from 0-Day
Checked Fact-Check Fact-Check Narr. Peak Fact-Checks
Politifact 6,231 6 55.0 4.0 110
Reuters 9,604 3 49.0 0.0 647
AP News 230 15 83.0 3.0 8
TABLE 10: Efficacy of fact-checking websites. All three websites
most commonly fact-check—by the number of articles with the
same narrative as the fact-check—the articles of qresear.ch (433 ar-
ticles), gatesofvienna.net (414), dailymail.co.uk (406).
Politifact [94], Reuters [95], and APNews [96], respectively.
To augment our system to perform fact-checking (i.e., deter-
mine whether a fact-check article refutes a given narrative),
we additionally train a DeBERTa-based [97] classifier on
the FEVER [98] dataset that takes a claim (i.e., an article)
and a query (i.e., a fact-check) and labels the query as
either supporting the claim, refuting the claim, or not having
enough information to say anything about the claim. Using
10% of the FEVER dataset as a held-out test set, our
DeBERTa-based model achieves an overall 90.7% accuracy
on this test set (90.5% precision in labeling refutations).
For each fact-checking article, as with articles from
unreliable websites, we divide the article into its constituent
passages and embed them utilizing our MPNet model. We
consider a narrative to have been addressed by a fact-checker
if the fact-checker writes about the narrative. We note that
articles frequently “fact-check” or “add context” to multiple
narratives. To provide fact checkers with the greatest number
of “opportunities” to fact-check a narrative, we map each
fact-check passage to all articles above our cosine similarity
threshold of 0.60 rather than map the fact-check passage
to only the single closest narrative. After mapping these
fact-checking passages to our set of articles, we utilize our
DeBERTa-based fact-checking classifier to ensure that the
corresponding “fact-check” refutes the information of the
corresponding unreliable news article passage. We provide
an example of an identified fact-check below. To ensure that
our model is able to properly identify “fact-checks”, we
manually validate 100 random fact-check-article refutation
pairs, finding that 94% of them are indeed refutations.
Article Passage: This is a shining example and a small part of why it is so vitally
important to find the underlying cause of the fraud that took place both in November
2020 and the lead-up to that election.
Fact-Check: THE FACTS: To be clear, no widespread corruption was found and
no election was stolen from Trump.
As seen in Table 10, on average, narratives can spread
one to two months before being fact-checked by these
reputable websites. Furthermore, on average both Politifact
and AP News write about stories after they have peaked
in popularity; AP News, with the fewest fact-checks, writes
about narratives right as they peak in popularity. We fur-
ther see a heavy overlap between the narratives that each
website fact-checks. Reuters and Politifact have an overlap
of 2,646 stories/narratives; AP News and Politifact, have an
overlap of 137 narratives; and Reuters and AP News have
an overlap of 141 narratives. Furthermore, the unreliable
websites that have articles most commonly fact-checked
by the three fact-checking organizations are the same: qre-
sear.ch (433 articles), gatesofvienna.net (414), and daily-
mail.co.uk (406). This underscores that these fact-checking
websites are duplicating effort, often fact-checking the same
narratives [99]. We note, however, that while narratives
often spread for long periods before being fact-checks, the
number of articles, on average, is often low (3–15 articles).
We thus see that many fact-checkers are effective at fact-
checking narratives when they peak in popularity, but often
understandably do not fact-check narratives that have just
begun to spread among different unreliable news websites.
We see that many narratives spread for long periods
on unreliable news websites before they are fact-checked
near their narrative peak. However, our system can surface
these narratives to fact-checkers long before they peak in
popularity, aiding in the fact-checking organizations’ typi-
cal workflow in identifying potential misinformation. This
can enable fact-checkers to identify and address misleading
narratives concurrent to when they first rise in popularity.
7. Related Work
Our study builds on considerable prior work on both the
spread of misinformation online and language models. There
have been several past quantitative studies of the spread
of information online. Leskovec et al. identify the trends
in the propagation of “memes” [17]. They find that while
the majority of memes originate from mainstream websites,
key phrases that start on smaller blogs are often adopted by
larger platforms. Gomez-Rodriguez et al. adopt a cascade
transmission model and identify how best to estimate the
relative influence of different news outlets in spreading
stories [100]. Similar to our use of DP-Means, prior works
have utilized CluStream among other clustering techniques
to track information or news over time [101]–[103]. For
example, Curiskis et al. [104] utilize document clustering
based on dictionaries to track topics.
Analyzing the Spread of Misinformation. Several works
have tracked the spread and impact of misinformation. Shu
et al. [105] present the largest overall overview of mis-
information detection issues, presenting various paradigms
for tracking and labeling misinformation. These include
tracking news content features and social content features.
For example, Cao et al. [106] and Meel et al. [107] explore
utilizing image and text-based features to label misinforma-
tion. Abdali et al., in contrast, use screenshots of websites
to identify the trustworthiness of websites and label mis-
information [108]. Extensive work has studied individual
campaigns that spread unreliable information, on topics like
QAnon [5], [49], Syrian White Helmets [34], the Russo-
Ukrainian War [39], [66], and COVID-19 [109].
Recent work from the security community has focused
on identifying and curbing misinformation. Kaiser et al. [13]
studied how borrowing techniques from the security warning
landscape might help to inform mis/disinformation warn-
ings. Paudel et al. [14] recently demonstrated how tech-
niques like Learning To Rank (LTR) can be used to soft-
moderate misinformation on Twitter. On the human-level,
Sharevski et al. identified folk models of misinformation on
social media that could inform potential defenses [110].
Language Models, Semantic Search, and Topic Analysis.
Many previous topic analysis methods have been built on
Latent Dirichlet Allocation (LDA). Albalawi et al. show
that LDA is one of the most effective methodologies for
extracting topics from short text data compared to other
computationally light alternatives proposed within the last
decade (e.g., LSA, LDA, NMF, PCA, RP) [111]. Meng
et al. [112], Angelov [113], and Grootendorst [64] have
enabled users to perform topic modeling utilizing large
language models. Utilizing these techniques and online doc-
ument clustering [114], [115], others have performed robust,
but smaller scoped semantic analysis (e.g., on Russian dis-
information campaigns [39], [53]).
8. Discussion and Conclusion
In this work, we introduced and validated a new, scalable
methodology for tracking news narratives online. Applying
the methodology to study the stories published on 1,334 un-
reliable news websites during 2022, our work shows how
a large-scale, quantitative analysis can identify propagation
patterns and significant players that may otherwise have
been difficult to uncover through qualitative investigations
of individual disinformation campaigns. Specifically, we
showed that less frequented websites and fringe social me-
dia platforms can have marked effects on amplifying the
narratives discussed on unreliable news websites.
Our study also highlights the need to programmatically
detect the rise of false narratives in real time. Prior work
has shown that misinformation can spread ten times faster
than legitimate news [6] and our analysis finds that false
narratives can often start on small, seemingly unpopular
websites. In many cases, these false narratives spread for
months online before being fact-checked. As such, we are
exploring how best to publicly and continuously release
real-time updates of our narrative analyses on an online
dashboard while protecting against misuse (e.g., use in AI
training models [116] or targeted misinformation chatbots).
While our study illustrates the potential for program-
matically tracking news narratives, it also simultaneously
surfaces areas for further research. For example, as found
in past works [39], [117], though our approach can identify
precise stories/narratives within our dataset, medical infor-
mation poses challenges for large language models like MP-
Net. For example, one of the misclassifications (Narrative 6
in Table 3) concerned COVID-19 rather than Monkeypox.
Given the high knowledge level needed in understanding
medical misinformation, past works have recommended uti-
lizing models specifically trained for medical misinforma-
tion for topic analysis of these stories [117]. We hope that
the potential of and demonstrated need for programmatic
approaches for tracking news narratives and misinformation
online motivates further work on these topics.
References
[1] Z. Stanton, “You’re living in the golden age of
conspiracy theories - politico,” 6 2020. [Online]. Available:
https://www.politico.com/news/magazine/2020/06/17/conspiracy-
theories-pandemic-trump-2020-election-coronavirus-326530
[2] A. Bovet and H. A. Makse, “Influence of fake news in twitter during
the 2016 us presidential election,” Nature Communications, 2019.
[3] P. Ball and A. Maxmen, “The epic battle against coronavirus mis-
information and conspiracy theories.” Nature, 2020.
[4] S. Banaji, R. Bhat, A. Agarwal, N. Passanha, and M. Sad-
hana Pravin, “Whatsapp vigilantes: An exploration of citizen re-
ception and circulation of whatsapp misinformation linked to mob
violence in india,” 2019.
[5] H. W. Hanley, D. Kumar, and Z. Durumeric, “No calm in the storm:
investigating qanon website relationships,” in International AAAI
conference on Web and social media, 2022.
[6] S. Vosoughi, D. Roy, and S. Aral, “The spread of true and false
news online,” Science, vol. 359, no. 6380, pp. 1146–1151, 2018.
[7] K. Thomas, D. Akhawe, M. Bailey, D. Boneh, E. Bursztein, S. Con-
solvo, N. Dell, Z. Durumeric, P. G. Kelley, D. Kumar et al., “SoK:
Hate, harassment, and the changing landscape of online abuse,” in
IEEE Symposium on Security and Privacy, 2021.
[8] M. E. Zurko, “Disinformation and reflections from usable security,”
IEEE Security & Privacy, vol. 20, no. 3, pp. 4–7, 2022.
[9] M. Rajdev and K. Lee, “Fake and spam messages: Detecting mis-
information during natural disasters on social media,” in Intl. Conf.
on Web Intelligence and Intelligent Agent Technology, 2015.
[10] L. Wu, F. Morstatter, K. M. Carley, and H. Liu, “Misinforma-
tion in social media: definition, manipulation, and detection,” ACM
SIGKDD Explorations Newsletter, vol. 21, no. 2, pp. 80–90, 2019.
[11] M. H. Saeed, S. Ali, J. Blackburn, E. De Cristofaro, S. Zannettou,
and G. Stringhini, “Trollmagnifier: Detecting state-sponsored troll
accounts on reddit,” in IEEE Symposium on Security and Privacy.
[12] A. Hounsel, J. Holland, B. Kaiser, K. Borgolte, N. Feamster, and
J. Mayer, “Identifying disinformation websites using infrastructure
features,” in USENIX Workshop on Free and Open Communications
on the Internet, 2020.
[13] B. Kaiser, J. Wei, E. Lucherini, K. Lee, J. N. Matias, and J. Mayer,
“Adapting security warnings to counter online disinformation,” in
30th USENIX Security Symposium, 2021.
[14] P. Paudel, J. Blackburn, E. De Cristofaro, S. Zannettou, and
G. Stringhini, “Lambretta: learning to rank for twitter soft mod-
eration,” in IEEE Symposium on Security and Privacy, 2023.
[15] S. Zannettou, T. Caulfield, E. De Cristofaro, M. Sirivianos,
G. Stringhini, and J. Blackburn, “Disinformation warfare: Under-
standing state-sponsored trolls on twitter and their influence on the
web,” in World wide web conference, 2019.
[16] F. Plasser, “From hard to soft news standards? how political jour-
nalists in different media systems evaluate the shifting quality of
news,” Harvard International Journal of Press/Politics, 2005.
[17] J. Leskovec, L. Backstrom, and J. Kleinberg, “Meme-tracking and
the dynamics of the news cycle,” in 15th ACM SIGKDD interna-
tional conference on Knowledge discovery and data mining, 2009.
[18] K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu, “Mpnet: Masked and
permuted pre-training for language understanding,” Adv. in Neural
Information Processing Systems, 2020.
[19] Z. Durumeric, E. Wustrow, and J. A. Halderman, “ZMap: fast
internet-wide scanning and its security applications,” in 22nd
USENIX Security Symposium, 2013.
[20] D. Moore, V. Paxson, S. Savage, C. Shannon, S. Staniford, and
N. Weaver, “Inside the slammer worm,” IEEE Security & Privacy,
2003.
[21] S. Meiklejohn, M. Pomarole, G. Jordan, K. Levchenko, D. McCoy,
G. M. Voelker, and S. Savage, “A fistful of bitcoins: characterizing
payments among men with no names,” in ACM Internet measure-
ment conference, 2013.
[22] C. Kanich, C. Kreibich, K. Levchenko, B. Enright, G. M. Voelker,
V. Paxson, and S. Savage, “Spamalytics: An empirical analysis of
spam marketing conversion,” in 15th ACM conference on Computer
and communications security, 2008.
[23] M. Motoyama, D. McCoy, K. Levchenko, S. Savage, and G. M.
Voelker, “An analysis of underground forums,” in ACM Internet
measurement conference, 2011.
[24] M. Antonakakis, T. April, M. Bailey, M. Bernhard, E. Bursztein,
J. Cochran, Z. Durumeric, J. A. Halderman, L. Invernizzi, M. Kallit-
sis et al., “Understanding the mirai botnet,” in 26th USENIX security
symposium, 2017.
[25] D. McCoy, A. Pitsillidis, J. Grant, N. Weaver, C. Kreibich, B. Krebs,
G. Voelker, S. Savage, and K. Levchenko, “PharmaLeaks: Under-
standing the business of online pharmaceutical affiliate programs,”
in 21st USENIX Security Symposium.
[26] S. Afroz, A. C. Islam, A. Stolerman, R. Greenstadt, and D. McCoy,
“Doppelg
¨
anger finder: Taking stylometry to the underground,” in
IEEE Symposium on Security and Privacy, 2014.
[27] E. Zeng, T. Kohno, and F. Roesner, “Bad news: Clickbait and
deceptive ads on news and misinformation websites,” in Workshop
on Technology and Consumer Protection, 2020.
[28] N. Heninger, Z. Durumeric, E. Wustrow, and J. A. Halderman,
“Mining your Ps and Qs: Detection of widespread weak keys in
network devices,” in 21st USENIX Security Symposium, 2012.
[29] C. Jack, “Lexicon of lies: Terms for problematic information,” Data
& Society, vol. 3, no. 22, pp. 1094–1096, 2017.
[30] S. Jiang and C. Wilson, “Linguistic signals under misinformation
and fact-checking: Evidence from user comments on social media,”
ACM CSCW, 2018.
[31] S. Lewandowsky, U. K. Ecker, C. M. Seifert, N. Schwarz, and
J. Cook, “Misinformation and its correction: Continued influence
and successful debiasing,” Psychological science in the public in-
terest, vol. 13, no. 3, pp. 106–131, 2012.
[32] H. Allcott, M. Gentzkow, and C. Yu, “Trends in the diffusion of
misinformation on social media,” Research & Politics, 2019.
[33] S. Z. Akbar, A. Panda, D. Kukreti, A. Meena, and J. Pal, “Misinfor-
mation as a window into prejudice: Covid-19 and the information
environment in india,” CSCW, 2021.
[34] K. Starbird, A. Arif, T. Wilson, K. Van Koevering, K. Yefimova,
and D. Scarnecchia, “Ecosystem or echo-system? exploring content
sharing across alternative media domains,” in International AAAI
Conference on Web and Social Media, 2018.
[35] J. Allan, “Detection as multi-topic tracking,” Information Retrieval,
vol. 5, no. 2-3, pp. 139–157, 2002.
[36] P. Devine and K. Blincoe, “Unsupervised extreme multi label clas-
sification of stack overflow posts,” in 1st International Workshop on
Natural Language-based Software Engineering, 2022.
[37] H. Jelodar, Y. Wang, C. Yuan, X. Feng, X. Jiang, Y. Li, and L. Zhao,
“Latent dirichlet allocation (lda) and topic modeling: models, appli-
cations, a survey,” Multimedia Tools and Applications, 2019.
[38] G. Leban, B. Fortuna, J. Brank, and M. Grobelnik, “Event registry:
learning about world events from news,” in 23rd International
Conference on World Wide Web, 2014.
[39] H. W. Hanley, D. Kumar, and Z. Durumeric, “Happenstance: Utiliz-
ing semantic search to track russian state media narratives about the
russo-ukrainian war on reddit,” in International AAAI conference on
web and social media, 2023.
[40] S. Miranda, A. Znotin¸
ˇ
s, S. B. Cohen, and G. Barzdins, “Multilingual
clustering of streaming news,” in Conference on Empirical Methods
in Natural Language Processing, 2018.
[41] C. Crawl, “Common crawl,” 10 2022. [Online]. Available:
https://commoncrawl.org/
[42] W. Min, B.-K. Bao, C. Xu, and M. S. Hossain, “Cross-platform
multi-modal topic modeling for personalized inter-platform recom-
mendation,” IEEE Transactions on Multimedia, 2015.
[43] R. Bal, S. Sinha, S. Dutta, R. Joshi, S. Ghosh, and R. Dutt,
“Analysing the extent of misinformation in cancer related tweets,”
in International AAAI Conference on Web and Social Media, 2020.
[44] Barret Golding, “Iffy index of unreliable sources,” https://iffy.news/
index/, 2022.
[45] M. Szpakowski, “Fake news corpus,” https://github.com/several27/
FakeNewsCorpus/, 2020.
[46] P. Staff, “Politifact’s guide to fake news websites and what they
peddle,” https://www.politifact.com/article/2017/apr/20/politifacts-
guide-fake-news-websites-and-what-they/, 2017.
[47] Aloisius Regen, “fake-news,” https://github.com/Aloisius/fake-news,
2017.
[48] Melissa Zidmars, “Misinformation and news literacy: Home,” https:
//library.athenstech.edu/fake, 2017.
[49] H. W. Hanley, D. Kumar, and Z. Durumeric, “A golden age: Conspir-
acy theories’ relationship with misinformation outlets, news media,
and the wider internet,” CSCW, 2023.
[50] J. Smith, H. Saint-Amand, M. Plamad
˘
a, P. Koehn, C. Callison-
Burch, and A. Lopez, “Dirt cheap web-scale parallel text from
the common crawl,” in 51st Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers), 2013.
[51] R. Dahlke, D. Kumar, Z. Durumeric, and J. Hancock, “Pie metrics:
quantifying the systematic bias in the ephemerality and inaccessi-
bility of web scraping content from url-logged web-browsing digital
trace data,” 2023.
[52] A. Piktus, F. Petroni, V. Karpukhin, D. Okhonko, S. Broscheit,
G. Izacard, P. Lewis, B. O
˘
guz, E. Grave, W.-t. Yih et al., “The
web is your oyster–knowledge-intensive nlp against a very large
web corpus,” arXiv preprint arXiv:2112.09924, 2021.
[53] H. W. Hanley and Z. Durumeric, “Partial mobilization: Tracking
multilingual information flows amongst russian media outlets and
telegram,” arXiv preprint arXiv:2301.10856, 2023.
[54] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Specia,
“Semeval-2017 task 1: Semantic textual similarity multilingual and
crosslingual focused evaluation,” in 11th International Workshop on
Semantic Evaluation, 2017.
[55] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors
for word representation,” in Empirical Methods in Natural Language
Processing (EMNLP), 2014.
[56] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-
training of deep bidirectional transformers for language understand-
ing,” in North American Chapter of the Association for Computa-
tional Linguistics: Human Language Technologies, Volume 1, 2019.
[57] D. Cer, Y. Yang, S.-y. Kong, N. Hua, N. Limtiaco, R. S. John,
N. Constant, M. Guajardo-Cespedes, S. Yuan, C. Tar et al., “Uni-
versal sentence encoder,” arXiv preprint arXiv:1803.11175, 2018.
[58] N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings
using siamese bert-networks,” in Conference on Empirical Methods
in Natural Language Processing and the 9th International Joint
Conference on Natural Language Processing, 2019.
[59] A. Rondinelli, L. Bongiovanni, and V. Basile, “Zero-shot topic
labeling for hazard classification,” Information, 2022.
[60] T. Gao, X. Yao, and D. Chen, “SimCSE: Simple contrastive learning
of sentence embeddings,” in Empirical Methods in Natural Lan-
guage Processing (EMNLP), 2021.
[61] N. Goel and R. Reddy, “Semeval-2022 task 8: Multi-lingual news
article similarity,” arXiv preprint arXiv:2208.09715, 2022.
[62] D. Vetter, J. J. Tithi, M. Westerlund, R. V. Zicari, and G. Roig,
“Using sentence embeddings and semantic similarity for seeking
consensus when assessing trustworthy ai,” arXiv:2208.04608, 2022.
[63] G. Bernard, C. Suire, C. Faucher, A. Doucet, and P. Rosso, “Tracking
news stories in short messages in the era of infodemic,” in Inter-
national Conference of the Cross-Language Evaluation Forum for
European Languages, 2022.
[64] M. Grootendorst, “Bertopic: Neural topic modeling with a class-
based tf-idf procedure,” arXiv preprint arXiv:2203.05794, 2022.
[65] O. Dinari and O. Freifeld, “Revisiting dp-means: fast scalable algo-
rithms via parallelism and delayed cluster creation,” in Uncertainty
in Artificial Intelligence, 2022.
[66] H. W. Hanley, D. Kumar, and Z. Durumeric, ““A Special Operation”:
A quantitative approach to dissecting and comparing different media
ecosystems’ coverage of the Russo-Ukrainian war,” in International
AAAI Conference on Web and Social Media, 2023.
[67] G. Bouma, “Normalized (pointwise) mutual information in colloca-
tion extraction,” Proceedings of GSCL, 2009.
[68] J. Kessler, “Scattertext: a browser-based tool for visualizing how
corpora differ,” in ACL, System Demonstrations, 2017.
[69] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed,
O. Levy, V. Stoyanov, and L. Zettlemoyer, “Bart: Denoising
sequence-to-sequence pre-training for natural language generation,
translation, and comprehension,” in 58th Annual Meeting of the
Association for Computational Linguistics, 2020.
[70] W. P. Staff, “Read the full opinion in dobbs v.
jackson women’s health o - washington post,” 6 2022.
[Online]. Available: https://www.washingtonpost.com/politics/
interactive/2022/roe-wade-decision-pdf/
[71] G. E. Center, “Pillars of russia’s disinformation and propaganda
ecosystem,” 2020.
[72] D. Masci, “Most poles accept jews as fellow citizens and neighbors
— pew research center,” 3 2018. [Online]. Available: https:
//www.pewresearch.org/fact-tank/2018/03/28/most-poles-accept-
jews-as-fellow-citizens-and-neighbors-but-a-minority-do-not/
[73] A. Perrone and D. Loucaides, “A key source for covid-
skeptic movements, the epoch times yearns for a global
audience - coda story,” 3 2022. [Online]. Available: https:
//www.codastory.com/disinformation/epoch-times/
[74] T. Daigle, “Canadian professor’s website helps russia spread
disinformation, says u.s. state department — cbc news,” 4
2021. [Online]. Available: https://www.cbc.ca/news/science/russian-
disinformation-global-research-website-1.5767208
[75] P. Baker and M. Haberman, “In torrent of falsehoods, trump
claims election is rigged,” 11 2020. [Online]. Available: https:
//www.nytimes.com/2020/11/05/us/politics/trump-presidency.html
[76] F. Nielsen, “On a generalization of the jensen–shannon divergence
and the jensen–shannon centroid,” Entropy, 2020.
[77] X. Que, F. Checconi, F. Petrini, and J. A. Gunnels, “Scalable com-
munity detection with the louvain algorithm,” in IEEE International
Parallel and Distributed Processing Symposium, 2015.
[78] K. Ruth, D. Kumar, B. Wang, L. Valenta, and Z. Durumeric, “Top-
pling top lists: Evaluating the accuracy of popular website lists,” in
22nd ACM Internet Measurement Conference, 2022.
[79] K. Ruth, A. Fass, J. Azose, M. Pearson, E. Thomas, C. Sadowski,
and Z. Durumeric, “A world wide view of browsing the world wide
web,” in 22nd ACM Internet Measurement Conference, 2022.
[80] K. J
¨
arvelin and J. Kek
¨
al
¨
ainen, “Cumulated gain-based evaluation of
ir techniques,” ACM Transactions on Information Systems, 2002.
[81] M. A. Little and R. Badawy, “Causal bootstrapping,” arXiv preprint
arXiv:1910.09648, 2019.

[82] M. Zapotosky and S. S. Hsu, “Mueller prosecutor says special
counsel ‘could have done more’ to hold trump accountable,”
09 2020. [Online]. Available: https://www.washingtonpost.com/
national-security/andrew-weissmann-book-mueller-trump/2020/09/
21/6a7967e8-fc10-11ea-b555-4d71a9254f4b story.html
[83] J. Murphy, “Emergencies act: Us was ’worried’ over canada
freedom convoy protests,” 11 2022. [Online]. Available: https:
//www.bbc.com/news/world-us-canada-63736482
[84] A. Glaser, “8chan is back as 8kun, but its racist users found
other places to go.” https://slate.com/technology/2019/11/8chan-
8kun-white-supremacists-telegram-discord-facebook.html, 2019.
[85] A. Zelenkauskaite, P. Toivanen, J. Huhtam
¨
aki, and K. Valaskivi,
“Shades of hatred online: 4chan duplicate circulation surge during
hybrid media events,” First Monday, 2021.
[86] D. V. Zandt, “Media Bias Fact Check,” https:
//mediabiasfactcheck.com/the-unz-report/, 2022.
[87] ——, “Media Bias Fact Check,” https://mediabiasfactcheck.com/
before-its-news/, 2022.
[88] ——, “Media Bias Fact Check,” https://mediabiasfactcheck.com/
the-truth-seeker/, 2022.
[89] T. N. Y. Times, “The facts about the attack on paul pelosi,
according to prosecutors - the new york times,” 11 2022.
[Online]. Available: https://www.nytimes.com/article/pelosi-paul-
nancy-attack-facts.html
[90] G. Kessler, “Fact-checking movement grapples with a world awash
in false claims,” https://www.washingtonpost.com/politics/2022/
06/29/fact-checking-movement-grapples-with-world-awash-false-
claims/, 2022.
[91] D. Zlatkova, P. Nakov, and I. Koychev, “Fact-checking meets faux-
tography: Verifying claims about images,” in Conf. on Empirical
Methods in NLP and the 9th Intl. Joint Conf. on NLP, 2019.
[92] B. Nyhan and J. Reifler, “When corrections fail: The persistence of
political misperceptions,” Political Behavior, 2010.
[93] H. Rashkin, E. Choi, J. Y. Jang, S. Volkova, and Y. Choi, “Truth
of varying shades: Analyzing language in fake news and political
fact-checking,” in Proceedings of the 2017 conference on empirical
methods in natural language processing, 2017, pp. 2931–2937.
[94] Politifact Staff, “Politifact latest fact checks,” https:
//www.politifact.com/factchecks/list/, 2022.
[95] Retuers Staff, “Reuters fact check,” https://www.reuters.com/fact-
check, 2022.
[96] “AP Fact Check,” https://apnews.com/hub/ap-fact-check, 2022.
[97] P. He, J. Gao, and W. Chen, “Debertav3: Improving deberta us-
ing electra-style pre-training with gradient-disentangled embedding
sharing,” in 11th Intl. Conf. on Learning Representations, 2022.
[98] J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “Fever:
a large-scale dataset for fact extraction and verification,” in Con-
ference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, 2018.
[99] D. Graves, “Understanding the promise and limits of automated fact-
checking,” 2018.
[100] M. Gomez-Rodriguez, J. Leskovec, and A. Krause, “Inferring net-
works of diffusion and influence,” ACM Transactions on Knowledge
Discovery from Data (TKDD), vol. 5, no. 4, pp. 1–37, 2012.
[101] H. Tajalizadeh and R. Boostani, “A novel stream clustering frame-
work for spam detection in twitter,” IEEE Transactions on Compu-
tational Social Systems, 2019.
[102] A. Alsayat and H. El-Sayed, “Social media analysis using optimized
k-means clustering,” in IEEE 14th International Conference on Soft-
ware Engineering Research, Management and Applications, 2016.
[103] W. Fan, Z. Guo, N. Bouguila, and W. Hou, “Clustering-based online
news topic detection and tracking through hierarchical bayesian non-
parametric models,” in 44th International ACM SIGIR Conference
on Research and Development in Information Retrieval, 2021.
[104] S. A. Curiskis, B. Drake, T. R. Osborn, and P. J. Kennedy, “An
evaluation of document clustering and topic modelling in two online
social networks: Twitter and reddit,” Information Processing &
Management, 2020.
[105] K. Shu, A. Sliva, S. Wang, J. Tang, and H. Liu, “Fake news detec-
tion on social media: A data mining perspective,” ACM SIGKDD
explorations newsletter, 2017.
[106] J. Cao, P. Qi, Q. Sheng, T. Yang, J. Guo, and J. Li, “Exploring
the role of visual content in fake news detection,” Disinformation,
Misinformation, and Fake News in Social Media, pp. 141–161, 2020.
[107] P. Meel, H. Agrawal, M. Agrawal, and A. Goyal, “Analysing tweets
for text and image features to detect fake news using ensemble
learning,” in Intl. Conf. on Intelligent Computing and Smart Com-
munication, 2020.
[108] S. Abdali, R. Gurav, S. Menon, D. Fonseca, N. Entezari, N. Shah,
and E. E. Papalexakis, “Identifying misinformation from website
screenshots,” arXiv preprint arXiv:2102.07849, 2021.
[109] G. Madraki, I. Grasso, J. M. Otala, Y. Liu, and J. Matthews, “Char-
acterizing and comparing covid-19 misinformation across languages,
countries and platforms,” in The web conference, 2021.
[110] F. Sharevski, A. Devine, E. Pieroni, and P. Jachim, “Folk models of
misinformation on social media,” 2023.
[111] R. Albalawi, T. H. Yeap, and M. Benyoucef, “Using topic modeling
methods for short-text data: A comparative analysis,” Frontiers in
artificial intelligence, vol. 3, p. 42, 2020.
[112] Y. Meng, Y. Zhang, J. Huang, Y. Zhang, and J. Han, “Topic
discovery via latent space clustering of pretrained language model
representations,” in ACM Web Conference, 2022.
[113] D. Angelov, “Top2vec: Distributed representations of topics,” 2020.
[114] J. Yin, D. Chao, Z. Liu, W. Zhang, X. Yu, and J. Wang, “Model-
based clustering of short text streams,” in 24th ACM SIGKDD
international conference on knowledge discovery & data mining,
2018.
[115] D. M. Blei, T. L. Griffiths, and M. I. Jordan, “The nested chinese
restaurant process and bayesian nonparametric inference of topic
hierarchies,” Journal of the ACM (JACM), 2010.
[116] E. David, “News outlets demand new rules for ai training data,”
4 2023. [Online]. Available: https://www.theverge.com/2023/8/10/
23827316/news-transparency-copyright-generative-ai
[117] S. L. Isaac, G. Irving, and I. Gabriel, “Ethical and social risks of
harm from language models,” 2021.
[118] B. Liang, Q. Zhu, X. Li, M. Yang, L. Gui, Y. He, and R. Xu, “Jointcl:
A joint contrastive learning framework for zero-shot stance detec-
tion,” in 60th Annual Meeting of the Association for Computational
Linguistics (Volume 1: Long Papers), 2022.
[119] B. Kulis and M. I. Jordan, “Revisiting k-means: New algorithms via
bayesian nonparametrics,” arXiv:1111.0352, 2011.
[120] P. D. Turney, “Mining the web for synonyms: Pmi-ir versus lsa on
toefl,” in European conference on machine learning, 2001.
[121] A. Aizawa, “An information-theoretic perspective of tf–idf mea-
sures,” Information Processing & Management, 2003.

Appendix A.
Training with Unsupervised Contrastive Loss
To train our MPNet model, we utilize unsupervised
contrastive learning to better the quality of our embed-
dings [60]. For training, this is such that we embed each
example x
i
= (text
i
) ∈ D
News
(where text
i
is the text)
twice (with dropout both times) using MPNet by inputting
[CLS]text
i
[SEP ] and averaging the contextual word vec-
tors of the resulting output as a hidden vector h
i
and
˜
h
i
for text
i
as its representations. Then, given a set of hidden
vectors {h
i
}
N
b
i=0
and {
˜
h
j
}
N
b
j=0
(different dropout), where N
b
is the size of the batch, we perform a contrastive learning
step on that batch. This is such that for each Batch B, for
an anchor hidden embedding h
i
within the batch, the set of
hidden vectors h
i
,
˜
h
j
∈ B, vectors where i = j are positive
pairs. Other pairs where i ̸= j are considered negative pairs.
Within each batch B, the contrastive loss is computed across
all positive pairs in the batch such that:
L
contrastive
= −
1
N
b
X
h
i
∈B
l
c
(h
i
)
l
c
(h
i
) = log
P
j∈B
[i=j]
exp(
h
⊤
i
˜
h
j
τ ||h
i
||||
˜
h
j
||
)
P
j∈B
exp(
h
⊤
i
˜
h
j
τ ||h
i
||||
˜
h
j
||
)
where, as in prior work [118], we utilize a temperature τ =
0.07.
Appendix B.
Passage Pairs
0.45 Similarity
PASSAGE 1: The growing possibility that nuclear weapons might be used, as hostilities in Ukraine continue to
escalate, merits your full attention.
PASSAGE 2: Raising the alert level of Russian nuclear forces is a bonechilling development, Guterres declared.
The prospect of nuclear conflict, once unthinkable, is now back within the realm of possibility.
0.50 Similarity
PASSAGE 1: When you actually look at the bill and it says no sexual instruction to kids preK through three, how
many parents want their kids to have transgenderism or something injected into classroom instruction? DeSantis
said earlier this month.
PASSAGE 2: Parents watchdog group Parents Defending Education PDE has warned that a school district in
Minnesota is pushing transgender and pride books and materials on to children as young as three years old.
0.55 Similarity
PASSAGE 1: Protests in the Netherlands became violent with police cars being set ablaze as the public grows angry
with their enforcement of COVID edicts to restrict their civil liberties:
PASSAGE 2: Thousands of Dutch citizens lined up in the streets defiantly even after government officials banned
protest, using the neverending pandemic as an excuse to brutally crackdown on civil liberties.
0.60 Similarity
PASSAGE 1: The raid by over 30 plain clothes agents from the Southern District of Florida and the FBI s Washington
Field Office extended through the Trump family s entire 3,000squarefoot private quarters, as well as to a separate
office and safe, and a locked basement storage room in which 15 cardboard boxes of material from the White House
were stored.
PASSAGE 2: Donald Trump lamented Wednesday that the FBI blocked his lawyers from the property during the
raid at his Palm Beach, Florida residence and suggested that agents may have ’planted’ evidence.
Figure 7: Example of passage pairs at different levels of cosine
similarities.
Appendix C.
DP-Means Algorithm
DP-Means [119] is a non-parametric extension of the
K-means algorithm that does not require the specification
of the number of clusters a priori. Within DP-Means, when
a given datapoint is a chosen parameter λ away from the
closest cluster, a new cluster is formed. Dinari et al. [65]
parallelize this algorithm by delaying cluster creation until
the end of the assignment step. Namely, instead of creating
a new cluster each time a new datapoint is discovered,
the algorithm instead determines which datapoint is furthest
from the current set of clusters and then creates a new cluster
with that datapoint. By delaying cluster creation, the DP-
means algorithm can be trivially parallelized. Furthermore,
by delaying cluster creation, this version of DP-Means
avoids over-clustering the data (i.e., only the most disparate
datapoints create new clusters) [65].
Appendix D.
Pointwise Mutual Information
The PMI of a particular word word
i
in a cluster C
j
is
calculated as:
P MI(word
i
, C
j
) = log
2
P (word
i
, C
j
)
P (word
i
)P (c
i
)
where P is the probability of occurrence and a scaling
parameter α is added to the counts of each word. This
scaling parameter α prevents single-count or one-off words
in each cluster from having the highest PMI values. Given
the scale of our dataset and the number of clusters within
our dataset, we determine that a baseline count of 1 (α
=1) for each word in the full dictionary in each cluster led
to the best results [120]. We utilize this approach rather
than cluster-normalized TF-IDF as in other works [39], [64]
because class TF-IDF is dependent on document classes
being similar in length [64], [121] and the number of
articles within each of our clusters varies widely. PMI finds
the distinct characteristics of individual clusters and is not
dependent on how often words appear in other individual
clusters, avoiding this issue.
Appendix E.
JS-Divergence
Formally JS-Divergence between two distributions P and
Q is calculated as follows:
JS(P ||Q) =
1
2
KL(P ||
(P + Q)
2
) +
1
2
KL(Q||
(P + Q)
2
)
KL(P ||Q) =
X
x
P (x) log(
P (x)
Q(x)
)
For our purposes, given that every website does not address
every topic, as recommended in other works, we add a small
value ϵ = 0.1 to the counts of every website’s topics before
calculating each website’s probability distribution.

Appendix F.
Auto-Generated Summaries and Cluster Specificity
Narr. Keywords Auto-Generated Summary Random Sample Passage
1 trudeau, motion,
151, 185,
emergency,
The Canadian Parliament voted Monday night to approve Prime Minister Justin Trudeau’s
motion to invoke the Emergencies Act by a vote of 185 for and 151 against.
On Monday night, Canada’s parliament voted to confirm Prime Minister Trudeau’s
declaration of the Emergencies Act in response to the freedom protests that have swept
across the nation for three weeks.
2 manchin, filibuster,
schumer, sinema,
senate
Republicans and other critics immediately started to wonder: If Democrats extract what
they want out of Manchin, couldn’t even a small number of them promptly refuse to go
along with the secondary assurances he’s been promised?
[The pipeline Manchin was promised] would require passage of legislation that would
overhaul the permitting process for energy infrastructure, according to The American
Prospect, a liberal website. Apparently, progressives in the House are not keen on
supporting a measure that could undercut the IRA s down payment on clean energy by
accelerating approval for energy projects that could ramp up U.S. fossil fuel production
and exports of natural gas, The American Prospect reported.
3 agrawal, musk,
parag, ceo, twitter
Twitter CEO Parag Agrawal tweeted he was ”excited” that Musk would join Twitter’s
board after it was revealed that Musk bought a 9.2 percent stake in the company, and in
doing so became its largest shareholder.
When Musk’s takeover of Twitter became official, Agrawal and Bret gave comments
alongside the Tesla CEO.
4 capitol, committe,
hearing, select,
january
The House of Representatives committee investigating the Jan. 6, 2021, attack on the
U.S. Capitol is planning to hold its next hearing on Sept. 28.
The U.S. House of Representatives select committee investigating the deadly Jan. 6, 2021,
attack on the Capitol will conduct its next hearing on Oct. 13, the panel said in a statement
on Thursday.
5 smith, slap, black,
oscar, rock
Apparently, whites can’t be outraged by Will Smith s slap without being racist. And never
mind that plenty of blacks including Kareem Abdul-Jabbar were also outraged
I elaborated that Will Smith proved he believes violence is the way to handle disagreement.
He makes blacks look bad his slap reinforces the widely held stereotype that blacks are
violent. He shamed AMPAS before the world.
6 extremist,
maryland, walkby,
virginia, protest
The group that calls itself Ruth Sent Us announced its plans on a website to harass the
justices. It said: Announcing Walkby Wednesday, May 11, 2022!At the homes of the six
extremist justices, three in Virginia and three in Maryland.
RSU subsequently announced a WalkBy Wednesday protest on May 11, to be held in
front of the homes of the six extremist justices
7 cornyn, boo, con-
vent, texas, gop
U.S. Senator John Cornyn RTexas was loudly booed at the Republican Party of Texas
Convention in Houston, where the state GOP adopted a resolution condemning the
bipartisan gun control framework he has negotiated in the Senate.
Very loud boos for John Cornyn as he takes the stage at the TexasGOP convention. Cornyn
has faced opposition within the party for working with Democrats on a gun package after
the shooting in Uvalde.
8 threat, truss, china,
uk, britain
Prime Minister Liz Truss is for the first time due to officially declare China a threat to the
UK within days. The designation would be a formal update to former PM Boris Johnson
s Integrated Review of Defense and Foreign Policy published in March 2021.
On October 11, The Guardian reported that the Liz Truss government is going to
formally designate China a national ”threat” to Britain in its upcoming strategic defense
review. Under former Prime Minister Boris Johnson, China was named just a ”systemic
competitor.
9 lithuania, vilniu,
baltic, beijing,
export
China has called for a corporate boycott of the small Baltic nation. The move is in
retaliation for Lithuania’s decision to open a Taiwanese representative office in its capital
of Vilnius in November 2021.
In a letter last month, the GermanBaltic Chamber of Commerce demanded that Lithuania
come to a constructive solution with the communist nation, saying per Reuters: The basic
business model of the companies is in question and some will have no other choice than
to shut down production in Lithuania.
10 curfew, quebec,
province, legault,
montreal
Quebec first imposed a COVID curfew on January 9, 2021, which was lifted on May 28.
Quebec is the only province in Canada to have imposed a curfew during the pandemic
Quebec is the first province to impose such a system on its citizens. It
´
s also the only
province in Canada that has a curfew in place.
Example of the auto-generated summaries and passages from a set of 10 random narrative clusters to illustrate the specificity and the precision of our approach.
Appendix G.
Paper Reviews
G.1. Summary of Paper
This paper introduced a system to automatically track
news narratives spread online. The paper analyzed news
across over 1334 unreliable news sites and identified 52K
narratives. Using the data, the authors examined news sites
that amplify the narratives and showed how the information
can be used to help with fact-checking.
G.2. Scientific Contributions
1) Creates a New Tool to Enable Future Science
2) Provides a Valuable Step Forward in an Established
Field
G.3. Reasons for Acceptance
1) The paper provides a valuable step forward in an
established field. The paper shows an end-to-end
system to keep track of narratives of (fake) news
over a large number of unreliable news websites.
The authors collected months of data across more
than 1334 news websites and identified over 52K
narratives. The analysis provided new insights into
the impact of the characteristics of the outlets on
the efficacy of the propagation of narratives in terms
of origination and amplification and the roles that
social media sites (8kun and 4chan) play.
2) The paper creates a new tool to enable future
science. The narrative tracking system leverages a
range of NLP and clustering tools. The ability to
track different narratives can potentially help with
identifying new misinformation for fact-checkers to
audit. The authors plan to make the data available
to researchers (and fact-checkers).
